

はじめに
こちらは STORES アドベントカレンダーの12/15日分の記事となります。
STORES 予約 のバックエンドエンジニアをしている矢作です。
私がこのプロダクトの開発に携わり出してから約3年半ほど経過しております。
その中で何度かデプロイパイプラインの更新が発生しており、今回は自分が把握している中でどう変わっていったのかについてまとめてみました。
各自のローカルPCからcap deploy
Railsで開発されている方であれば馴染みのある方も多いcapistranoを利用してデプロイしていました。
正確には今も一部でcapistranoを利用したデプロイが残っています。
deployに必要な公開鍵を各開発者に配布し、各開発者の手元のPCからcap ${env} deployコマンドを発行してデプロイを行なっていました。
Github Actionsなどにデプロイ用の処理を寄せている場合、Githubが落ちているとデプロイが出来なくなってしまうので、手元にインターネットに繋がっている環境構築済みのPCさえあればデプロイが可能なこのデプロイルートが今も残されていれば便利だなと思うときもあります。
ChatOpsの導入
どういった背景からかは忘れましたが、Slack経由でデプロイしたいよねとなり、現在の原型となるChatOpsでのデプロイフローが整備されました。
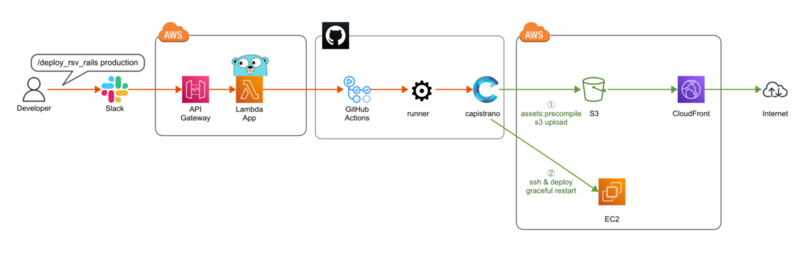
具体的なフローは以下のようになります。
*1
- Slack上でデプロイ用のコマンドを入力
- SlackがAWS上のLambdaの前段に配置されているAPI Gatewayによって公開されたAPIに対してリクエストを発行する
- API GatewayからLambdaが起動される
- Lambdaからデプロイ用のスクリプトが書かれたGithub Actionsをトリガーする
SlackとGithub Actionsの間に挟まるLambdaはGolangで書かれており、Lambda本体とAPI Gatewayを含むAWS上の各種リソースはAWS SAMを利用して構築しております。
流れを図に書き起こすとこんな感じです。
ChatOpsの機能を拡充
ロールバック用のコマンドを整備
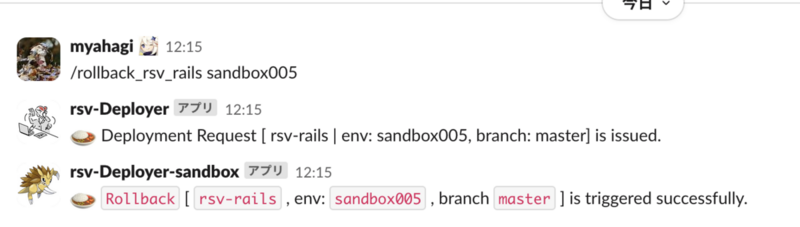 バックエンドのRailsサーバーをコンテナ化して、CodeDeployによるBlue/Greenデプロイを行うようにしたことで、指定した時間1つ前の環境が待機中として存続し続けるようになりました。
それに伴い、デプロイ後に何か問題が発生したことを待機時間内に気づくことが出来たら、直ちに1つ前の環境に戻すことで影響を抑えることが出来ます。*2
バックエンドのRailsサーバーをコンテナ化して、CodeDeployによるBlue/Greenデプロイを行うようにしたことで、指定した時間1つ前の環境が待機中として存続し続けるようになりました。
それに伴い、デプロイ後に何か問題が発生したことを待機時間内に気づくことが出来たら、直ちに1つ前の環境に戻すことで影響を抑えることが出来ます。*2
とはいえ、この対応をしようとした場合、AWSのマネジメントコンソールを開いて、CodeDeployの対象のデプロイメントの詳細画面を開き、デプロイを停止してロールバックを押す といった手順を踏む必要があるため、ちょっとめんどくさいです。
(まずAWSのマネジメントコンソールにへのアクセスがその日初めてとかだとすると、そこでログインも求められるため余計にめんどくさい)
そもそもCodeDeployの詳細画面からロールバックが行えることを頑張って普及する必要があります。
なので、Slackからコマンド一発で済ませられるといろいろ楽だな と思ってロールバックを行えるコマンドを増やしました。
コンテナ化によって得られるようになったメリットな側面が大きいですが、これによりあまりAWSのサービスに明るくない開発者でもカジュアルにロールバックが行えるため、直前のリリースに問題となる対応が含まれていたパターンにおいては、復旧までの時間を短縮出来ているのではと思います。
デプロイ後に一定時間次のデプロイを受け付けないようにするロック機構を整備
前提として、STORES 予約 の開発チームは意味のある単位でPRを細かく分離し、1つのPRがマージされる度にリリースを行うといった開発スタイルをとっています。
product.st.inc
これにより、コードレビューが行いやすくなるのと、リリース後に何か問題が発生した際に、直前の変更の粒度が小さいことで、問題となった変更点を察知しやすいといった効果を得られています。
一方で、開発に携わるメンバーも増えてきた中で、直前のリリース作業が行われている間に次のリリースコマンドが発火されたり、不具合を切り戻したいのに次のリリースが完了するまで身動きが取りにくい といった課題が発生するようになってきました。
また、CodeDeployは、同時に複数のデプロイを走らせることが仕様上出来ないため*3、直前のデプロイが進行中であったり、待機状態の間に、次のデプロイがトリガーされると、そのデプロイは却下されてしまいます。
こういった事象に対処するために、デプロイコマンドの発火後、一定期間は次のデプロイが行えないようにコマンドの受付をロックしたいよねとなりしました。
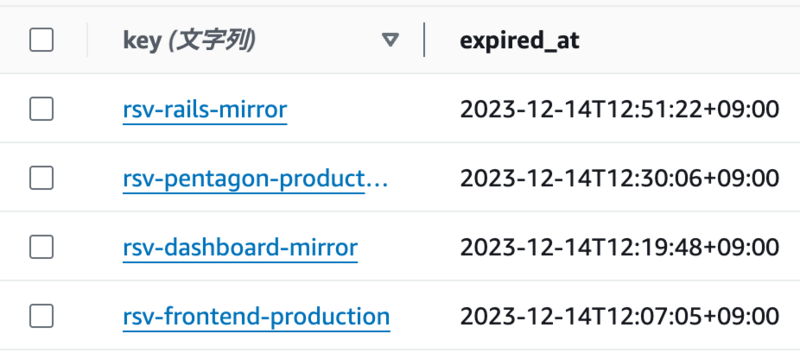
具体的には、DynamoDBと連動させて以下のようなkey, valueを持たせることで簡易的なロック機構として実現しました。
Slackコマンドからリクエストを受け、デプロイ用のGitHub actionsをトリガーする度に対象のkeyに対して、現在時刻 + ロックしておきたい時間をvalueとしてセットしています。
頻繁にリクエストが同時到達してくるユースケースではないため、排他制御等の考慮も省いています。
デプロイコマンドを発火したタイミングがロック中だった場合は、デプロイ処理がトリガーせずに以下のようなメッセージを返しています。
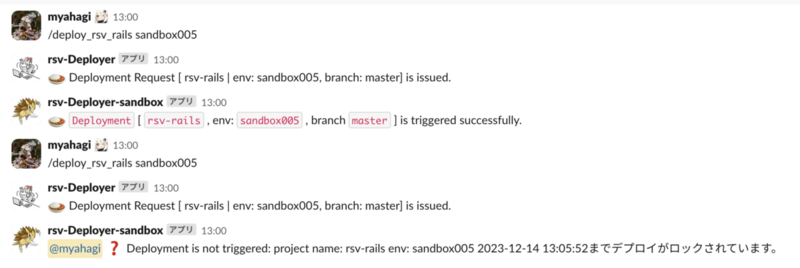
これにより、重複してデプロイを走らせてしまうことが大幅に減り、PRのマージ後はとりあえずデプロイコマンドを叩いてみることで次にデプロイが可能になるタイミングも知れるのでなかなか便利になったなと感じています。
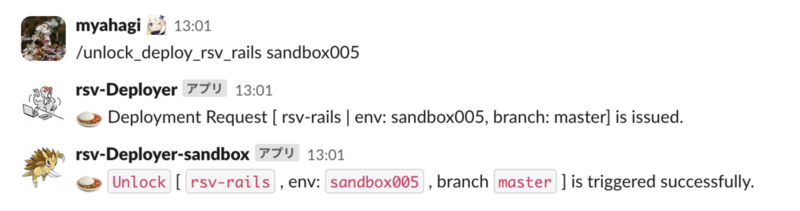
やんごとなき事情で前のデプロイ処理をキャンセルし、今すぐにデプロイを行いたいといった場面に備えて、ロックを解除できる機構も備わっております。
まとめ
ざっと記憶を元に振り返ってみましたが、現在のChatOpsのフローを中心に、PRマージ後にSlack上で打つべきリリースコマンドをメンション付きで教えてくれる通称「デプロイしてね」くん のような周辺システムも整備されたりと、手元でcap deployを走らせていた頃からは大分進歩したなと感じております。
product.st.inc
今後も、思いつきベースで痒い所に手が届くような機能の拡充をしていく予定ですが、ベースが大きく変わることはないかなと思っております。今だとLambdaの関数URLを利用することでAPI Gatewayをなくすことが出来たりするので、そういったものを活用して、機能は維持したまま管理が必要なリソースを減らしていきたいなと目論んでいます。