
はじめに
2024年1月にリテール(ネットショップ・レジ)部門からサービス(予約)部門に異動になった @ucks です。
異動してからはスマートリストという機能の開発を行っていて、5月6日に無事リリースできたのと、開発途中で障害に至ってしまった部分があるので、裏側を少し紹介しようかなと思います。
スマートリストとは
スマートリストの開発についての話を行う前に、まずはスマートリストについて簡単に説明しておきます。

スマートリストとは、特定の条件の顧客をラベリングする機能です。 早い話、最終予約日がいつ、予約回数が何回以上等の顧客の検索条件を保存しておいて、閲覧時にラベリングして、視認しやすくしたり、絞り込みやすくする機能です。 スマートリストを起点に、メール配信を行ったり、もしかすると今後何か新機能が追加されたりするかもしれません。

近々来店する人を見やすくして日々の業務を効率化したり、確認漏れ等の防止に役立ててもらったり、しばらく来店してない人を見やすくして、分析や改善に役立ててもらえればと思っています。
詳しくはSTORES Magazineを見ていただければと思います。
スマートリストの設計
スマートリストは、基本的には顧客検索機能の発展機能で、検索条件を保存しておく機能です。 また、顧客リストで、保存した条件に合致していた顧客の行に、一致したスマートリストを表示させる必要があります。
これらを実現するには、顧客リストの検索パラメータを何かしらの方法で保存し、簡単に検索条件に反映させたり、一覧表示した際に条件に合致した場合、ラベル情報を付与するだけで実現できます。
(実際の開発では画面をどうするか、どの様に検索条件を保存するか、保存した条件をどの様に検索条件に反映させるか、ラベル情報をどの様に付与するか、他の機能に影響があるかや今後の拡張性等を考えながら開発をしていくので、そんなに簡単にはいかないのですが…)
今回は、この中でも顧客リストで一致したスマートリストを表示する部分についての裏話を紹介します。
このスマートリストのラベルを表示するには、各顧客がどのスマートリストに合致しているかを求める必要があります。 顧客がどのスマートリストの条件に合致しているかを求めるには、大きく分けて下記の2パターンが考えられるかと思います。
- 保存している条件でDBに検索を行い検索結果と突合する
- 検索結果に対してRuby上で判別する

|

|
DBで検索を行う場合、DB負荷が高まる可能性があります。これは、何となく気が引けるかなと思います。 特に、このスマートリストは複数件保存することができ、スマートリスト数分検索を行うことになるのでパフォーマンスの観でに非常に不安が残ります。 ただ、Ruby上で判別するにしても、DBの検索クエリとRubyでの判別ロジックが同一であることを保証するのは、非常に難しい課題です。
また、合致結果を求めるタイミングもいくつかのパターンが考えられ、大きくは下記の2パターンに分けられるかと思います。
- 特定のタイミングで合致結果を求めキャッシュデータを生成しておく
- 顧客検索時に毎回計算する
事前にキャッシュデータを生成しておくと実際の検索時には、複雑な検索を行う必要がないので、DB負荷を抑えることができます。 ただし、キャッシュデータを作ったタイミングから表示までの間にデータが更新されてしまい、実際の状況と差分が発生する可能性があります。 そのため、定時に再計算を行うのか、特定の操作をした際に再計算を行うのか等、キャッシュデータの更新タイミングをよく考える必要があります。
今回は、検索内容が単純ではないため、DBの検索クエリとRubyでの判別ロジックの同一性を担保し続けるのは困難であり、今後の機能拡張時の開発量も考慮し、DBを使って検索を行う判断を行いました。
また、合致結果を求めるタイミングに関しては、顧客検索時に毎回計算する方法を選択しました。 これは、この機能の利用者が、理解力の高い方やずっと使い続けていて仕様を把握されている方から、その日に入ったばかりのアルバイトの方まで多岐に渡る可能性があり、誰が使ってもミスが起こりづらい様に、実際の状況と差分が発生しづらい方法を選択しました。
この時点で、検索方法、検索タイミング共にDBへの負荷が高い選択になっています。
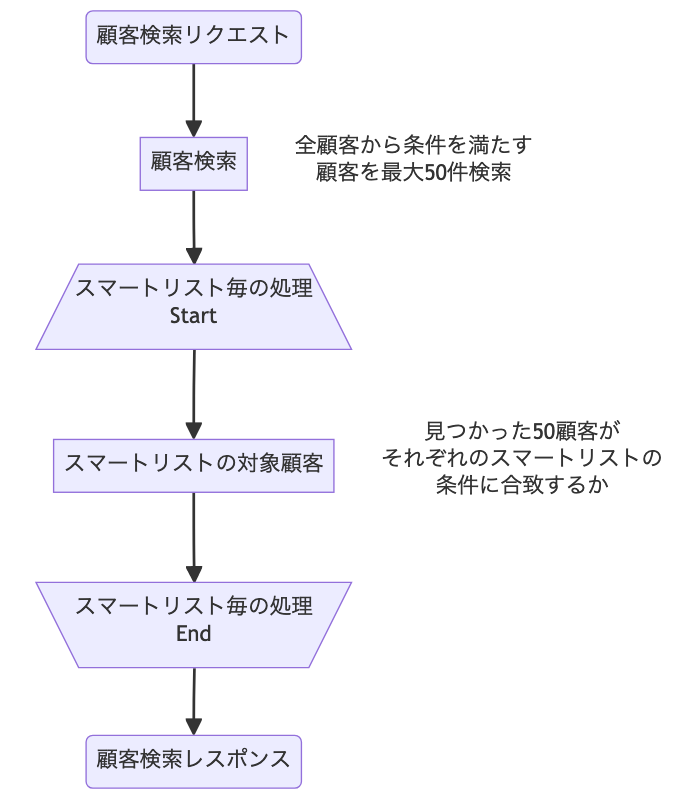
顧客リストで必要な処理を図示すると下記の様になります。

雑にRailsのコードに落とすと下記の様な感じでしょうか。
def CustomersController def index customers = current_user .tenant .customers .left_joins(略) .where(略) .page(params[:page]) .per(50) customer_smart_lists = Hash.new { |hash, key| hash[key] = [] } current_user .tennant .smart_lists .each do |smart_list| current_user .tenant .customers .where(smart_list.params) .pluck(:id) .each do |customer_id| customer_smart_lists[customer_id] << smart_list end end render json: customers.map do |customer| { id: customer.id, name: customer.name, smart_lists: customer_smart_lists[customer.id].map do |smart_list| { name: smart_list.name, } end } end end end # ※ あくまでイメージで実際のコードとは結構異なります
eachの中にeachがある上に、eachの中で重そうな顧客テーブルへの検索があります。 少し警戒してしまうと思います。
ただ、ここで少し考えてみます。
顧客がどのスマートリストの条件に合致しているか、という情報は、全ての顧客分必要ではなく、表示する顧客分の情報があれば十分です。 つまり、顧客検索を行った後、検索結果に対してのみスマートリストの合致判定を行えば、必要な情報が揃います。 全ての顧客に対して再検索を行う必要がありません。
STORES 予約の顧客リストは最大50件までしか一度に表示されません。 そのため、1つのスマートリストの条件に対して、最大で走査する必要のあるデータは最大50件です。
Rubyのコードも少し追加するだけで対応できます。
def CustomersController def index customers = current_user .tenant .customers .left_joins(略) .where(略) .page(params[:page]) .per(50) .load # load しておくと `customers.pluck(:id)` でクエリの発火が不要になる customer_smart_lists = Hash.new { |hash, key| hash[key] = [] } current_user .tennant .smart_lists .each do |smart_list| current_user .tenant .customers .where(smart_list.params) # ↓ これを追加 .where(customer_id: customers.pluck(:id)) .pluck(:id) .each do |customer_id| customer_smart_lists[customer_id] << smart_list end end : (略) end end
最大50件に絞った箇所の、SQLで表すと下記の様なクエリになるはずです。
SELECT * FROM `顧客` JOIN {{検索に必要なテーブル}} WHERE {{スマートリストの条件}} AND `顧客`.`ID` IN (1, 2, 3, ..., 50)
このクエリで、顧客が大量にあり、 顧客.ID にインデックスがあれば、基本的にはレコードを50件に絞れる 顧客.ID のインデックスが使われるはずです。
最終的に、スマートリストは最大20件保存できる仕様に落ち着いたので、全て合わせても50件×20回の1000件の走査で済みます。 顧客の件数は事業者にもよりますが、数千数万ある事業者もあるので、その事業者への検索と比較すると微々たるものです。
(それでもスマートリスト20件分クエリ投げるのは… 等思うところはありますが、それらの対応ついてはまた機会があれば… 実行時間やDB負荷については確認済みです)
これらの理由から、今回リリースしたスマートリストでは、顧客検索時にスマートリスト分DBへの検索を行いラベルを付与する選択を行いました。
検索の仕様変更
ここまで説明した様なことを考えながら、リリース目標に向け、機能開発を行っていました。 リリース予定日の2週間前には、基本的に機能は完成していて、QAテスト等を行っていました。
この時に、顧客検索が想定していた挙動でないことが発覚しました。 顧客リストでは、予約ページや予約回数、最終予約日を指定して絞り込めるのですが、「指定した予約ページの予約で予約回数、最終予約日」に合致した顧客を検索している想定が、「指定した予約ページに予約したことがある、かつ他の予約全て含めて、指定した予約回数、最終予約日」の顧客を検索する様になっていました。
例えば、下記の様なデータがあった際に、
| ID | テナントID | 名前 |
|---|---|---|
| 1 | 1 | 顧客1 |
| 2 | 1 | 顧客2 |
| ID | テナントID | 予約ページ名 |
|---|---|---|
| 1 | 1 | 予約ページ1 |
| 2 | 1 | 予約ページ2 |
| 3 | 1 | 予約ページ3 |
| ID | 顧客ID | 予約ページID | 予約日 |
|---|---|---|---|
| 1 | 1 | 1 | 2024-01-01 |
| 2 | 1 | 1 | 2024-01-07 |
| 3 | 1 | 2 | 2024-01-03 |
| 4 | 2 | 2 | 2024-01-05 |
| 5 | 2 | 2 | 2024-01-06 |
| 6 | 2 | 2 | 2024-01-07 |
予約したことのある予約ページ: 予約ページ1, 最終予約日: 2024-01-07 で絞り込みを行った際に、顧客1のみ検索に引っかかって欲しいところが、顧客2まで引っ掛かる様になっていました。
| ID | 名前 | 最終予約日 | 予約ページ1の最終予約日 |
|---|---|---|---|
| 1 | 顧客1 | 2024-01-07 | 2024-01-07 |
| 2 | 顧客2 | 2024-01-07 | NULL |
また、 予約したことのある予約ページ: [予約ページ1, 予約ページ2], 最終予約日: 2024-01-03 で絞り込みを行った際は、顧客1と顧客2共に検索に引っかかる予定でした。
| ID | 名前 | 最終予約日 | 予約ページ1の最終予約日 | 予約ページ2の最終予約日 |
|---|---|---|---|---|
| 1 | 顧客1 | 2024-01-07 | 2024-01-07 | 2024-01-03 |
| 2 | 顧客2 | 2024-01-03 | NULL | 2024-01-03 |
スマートリストは、検索条件を保存する機能なので、検索条件が保存された後にロジックが変更になった場合、保存した時とは異なる想定の結果になる可能性があります。 そのため、リリース前に、急遽検索ロジックを変更する必要が出てきました。
というわけで、ここから仕様変更に対応した設計を行なっていきます。
この検索条件を全てキャッシュするとなると 顧客数x予約ページ数^2 分のデータをキャッシュすることになります。
そのため、各予約ページの予約状況をキャッシュすることは難しそうです。
とりあえず、HAVING句で絞り込もうと思っても、結構複雑なクエリになりそうです。
SELECT * FROM `顧客` JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` WHERE `顧客`.`テナントID` = 1 GROUP BY `顧客ID`, `予約ページID` HAVING {{え、ここ難しくね?}} = '2024-01-07'
HAVING句に計算ロジックを入れてしまうと、計算結果を確認するためには、長いHAVING句の中身をSELECT句にコピーしなければならず、デバッグ時が面倒になります。 また、異なるカラムでグルーピングした結果で絞り込みたい要件が出てきた際に、競合してしまいます。
そのため、一旦、下記の様な集計テーブルを作れば、途中の計算結果も集計テーブルで確認できるので、デバッグも行いやすくなると考え、インラインビューを活用する方法を選択しました。
| 顧客ID | 予約ページID | 予約回数 | 最終予約日 |
|---|---|---|---|
| 1 | 1 | 2 | 2024-01-07 |
| 1 | 2 | 1 | 2024-01-02 |
| 2 | 1 | 3 | 2024-01-07 |
| 2 | 2 | 0 | NULL |
SELECT `顧客ID`, `予約ページID`, COUNT(`予約 `.`ID`) AS `予約回数`, MAX(`予約 `.`予約日`) AS 最終予約日 FROM `顧客` LEFT JOIN `予約ページ` LEFT JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` AND `予約`.`予約ページID` = `予約ページ`.`ID` WHERE `顧客`.`テナントID` = 1 GROUP BY `顧客ID`, `予約ページID`
ちなみに LEFT JOIN `予約ページ` というのがないと下記の様な結果になり、予約なしという検索ができなくなるため付与しています。
| 顧客ID | 予約ページID | 予約回数 | 最終予約日 |
|---|---|---|---|
| 1 | 1 | 2 | 2024-01-07 |
| 1 | 2 | 1 | 2024-01-02 |
| 2 | 1 | 3 | 2024-01-07 |
このインラインビューを使えば下記の様な形で検索ができるので、検索ロジックもシンプルに書けそうです。
SELECT DISTINCT `顧客`.* FROM `顧客` LEFT JOIN ( SELECT `顧客ID`, `予約ページID`, COUNT(`予約 `.`ID`) AS `予約回数`, MAX(`予約 `.`予約日`) AS 最終予約日 FROM `顧客` LEFT JOIN `予約ページ` LEFT JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` AND `予約`.`予約ページID` = `予約ページ`.`ID` WHERE `顧客`.`テナントID` = 1 GROUP BY `顧客ID`, `予約ページID` ) AS `予約状況` ON `予約状況`.`顧客ID` = `顧客`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約ページID` = 1 AND `予約状況`.`予約日` = '2024-01-07'
とりあえず、この方針で進めていきますが、よくよく考えてみると、予約ページが複数ある事業者さんの場合に、全部のページで予約したことがある人はほぼいない事に気づきます。
例えば、音楽教室でピアノコースとギターコースとドラムコースがあった時に、全てのコースで予約している人は、殆どいないという感じです。

このロジックで進めると最終予約日がなしの検索が使えない機能になってしまいます。 というわけで、またこの検索の仕様について、検討を行いました。
結果、指定した予約ページ全てまとめた時の最終予約日や予約回数で絞り込むことができれば、大凡のニーズに耐えられるのではという結論になりました。
つまり、予約したことのある予約ページ: 予約ページ1 & 予約ページ2で検索した際には下記の様な集計テーブルを作って検索すれば解決できそうです。
| ID | 名前 | 予約ページ1と予約ページ2合わせた最終予約日 |
|---|---|---|
| 1 | 顧客1 | 2024-01-07 |
| 2 | 顧客2 | 2024-01-07 |
集計用のSQLも、 予約ページID がインラインビュー内に移動し、GROUP BY から 予約ページID を消すだけという小さな修正で済みそうです。
SELECT DISTINCT `顧客`.* FROM `顧客` LEFT JOIN ( SELECT `顧客ID`, `予約ページID`, COUNT(`予約 `.`ID`) AS `予約回数`, MAX(`予約 `.`予約日`) AS 最終予約日 FROM `顧客` LEFT JOIN `予約ページ` LEFT JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` AND `予約`.`予約ページID` = `予約ページ`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約ページID` IN (1, 2) GROUP BY `顧客ID` ) AS `予約状況` ON `予約状況`.`顧客ID` = `顧客`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約日` = '2024-01-07'
このような形で、検索内容も変わったので、既存の検索パラメータとは別に、新規のパラメータを定義して、スマートリストリリース後は新規のパラメータに切り替えるようにしました。
これらの修正を行なって、想定している検索ができる様になりました。
高負荷時のハンドリング
検索ロジックがより複雑になったので、DB負荷は気になります。 EXPLAINの結果を見てみると、どうやらindexは使われていそうです。 ある程度データの多いテストアカウントでログインして動くことも確認しました。
とはいえ、本番環境では、複数のアクセスが同時に発生することにより、想定外の負荷がかかる可能性があります。 そのため、検索が一定以上かかった場合は、処理を中断し、他の処理のためにリソースを開けるためにオプティマイザヒントにより最大実行時間を付与することにしました。
def CustomersController def index customers = current_user .tenant .customers .optimizer_hints('MAX_EXECUTION_TIME(1000)') # これを追加 .where(customer_search_params) .page(params[:page]) .per(50) .load : (略)
SQLとしては下記の様な形になります。
SELECT /*+ MAX_EXECUTION_TIME(1000) */ DISTINCT `顧客`.* FROM `顧客` LEFT JOIN ( SELECT `顧客ID`, `予約ページID`, COUNT(`予約 `.`ID`) AS `予約回数`, MAX(`予約 `.`予約日`) AS 最終予約日 FROM `顧客` LEFT JOIN `予約ページ` LEFT JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` AND `予約`.`予約ページID` = `予約ページ`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約ページID` IN (1, 2) GROUP BY `顧客ID` ) AS `予約状況` ON `予約状況`.`顧客ID` = `顧客`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約日` = '2024-01-07'
ここまでの実装を終え、検証環境で動作確認を行い結果や負荷の検証を行いました。 負荷を高くし、想定以上に検索に時間がかかった場合はタイムアウトすることも確認しました。 EXPLAINでDBの実行計画も確認しindexを使わないスキャンが行われていないことも確認しました。
というわけで、ここまでの修正を本番環境にリリースを行いました。
そして障害へ
スマートリストは、使い方のイメージを持っていただくために、初期データを用意しています。
近々初めて来店される方を表す 初回予約の顧客 というリストと、来店されてから次回の予約がない方に何かしらアクションを取っていただくイメージで 要フォロー顧客 というリストを用意することになっていました。
これらのデータは、事前に生成していましたが、こちらの条件も検索の仕様変更に伴い再度見直しが行われ、パラメータの調整を行うことになりました。 このパラメータの調整に合わせて、前もって生成していたデータを全て書き換え直す必要があります。
というわけで、古い 初回予約の顧客 の条件から新しい 初回予約の顧客 の条件へ、古い 要フォロー顧客 の条件から新しい 要フォロー顧客 の条件に書き換える作業を行なっていました。
データの書き換え作業時は、DBに負荷を与える可能性があるので、Webサーバのレスポンスのレイテンシや書き込み用DBの負荷等のいくつかのメトリクスの確認を行いながら作業を進めていました。
監視していたメトリクスでは特に大きな変化はなく、書き換え作業を続けていました。 書き換えバッチを流していて、20分程経過したタイミングで、いきなり504エラー(Gateway Timeout)が増えたアラートを検知します。

↑ 03:00UTC過ぎから作業をしていたが、あるタイミングでいきなりエラーが増えた
エンジニアは調査を始めますが原因がわかりません。 とりあえず、直前の変更をリバートします。 504エラーは収まりません。
どうやらDBの負荷が高いらしいということで、プリセットの書き換えバッチも止めます。 504エラーは収まりません。
というわけで、ここまでの流れの中で見落としている部分が複数あり、それが原因で障害が発生してしました。
具体的には、以下の部分を見落としてしまっていました。
- 顧客検索時は最大実行時間が指定されているが、スマートリストの対象顧客の検索の最大実行時間の付与漏れ
- 予約ページの集計テーブルが50件に絞られていない
- プリセットデータを作り直した際に検索ロジックが変わる
まず、スマートリストの対象顧客の検索の最大実行時間の付与漏れについてですが、顧客全体の検索時にオプティマイザヒントを付与しましたが、スマートリストの対象顧客の検索には付与を忘れていました。 50件の顧客のIDを渡していますが、検索した結果から取得したIDを渡しているだけなので、オプティマイザヒントによる最大実行時間は渡されず、重いSQLが発火した際にすぐにタイムアウトされない様になっていました。
def CustomersController def index customers = current_user .tenant .customers .optimizer_hints(‘MAX_EXECUTION_TIME(1000)’) .left_joins(略) .where(略) .page(params[:page]) .per(50) .load customer_smart_lists = Hash.new { |hash, key| hash[key] = [] } current_user .tenant .smart_lists .each do |smart_list| current_user .tenant .customers .where(smart_list.params) # ↓ pluckの結果を渡しているので、customersからoptimizer_hintsは引き継がれない .where(customer_id: customers.pluck(:id)) .optimizer_hints(‘MAX_EXECUTION_TIME(1000)’) # これを忘れていた .pluck(:id) .each do |customer_id| customer_smart_lists[customer_id] << smart_list end end : (略) end end
次に、予約ページの集計テーブルが50件に絞られていない件についてですが、スマートリストの対象顧客のクエリにWHERE句でIDを指定しているだけです。 つまりSQLとしては下記の様になります。
SELECT /*+ MAX_EXECUTION_TIME(10) */ DISTINCT `顧客`.* FROM `顧客` LEFT JOIN ( SELECT `顧客ID`, `予約ページID`, COUNT(`予約 `.`ID`) AS `予約回数`, MAX(`予約 `.`予約日`) AS 最終予約日 FROM `顧客` LEFT JOIN `予約ページ` LEFT JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` AND `予約`.`予約ページID` = `予約ページ`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約ページID` IN (1, 2) GROUP BY `顧客ID` ) AS `予約状況` ON `予約状況`.`顧客ID` = `顧客`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約日` = '2024-01-07' AND `顧客`.`ID` IN (1, 2, 3, ..., 50)
確かに、一番外側のクエリではIDが絞り込まれていますが、 LEFT JOIN (略) AS '予約状況' の中は絞り込まれておらず、特定のテナント内の全ての顧客を捜査してしまっています。
下記の様に、予約状況の中にも顧客IDによるIN句が必要でした。
SELECT /*+ MAX_EXECUTION_TIME(10) */ DISTINCT `顧客`.* FROM `顧客` LEFT JOIN ( SELECT `顧客ID`, `予約ページID`, COUNT(`予約 `.`ID`) AS `予約回数`, MAX(`予約 `.`予約日`) AS 最終予約日 FROM `顧客` LEFT JOIN `予約ページ` LEFT JOIN `予約` ON `予約`.`顧客ID` = `顧客`.`ID` AND `予約`.`予約ページID` = `予約ページ`.`ID` WHERE `顧客`.`テナントID` = 1 AND `顧客`.`ID` IN (1, 2, 3, ..., 50) -- これが必要だった AND `予約状況`.`予約ページID` IN (1, 2) GROUP BY `顧客ID` ) AS `予約状況` ON `予約状況`.`顧客ID` = `顧客`.`ID` WHERE `顧客`.`テナントID` = 1 AND `予約状況`.`予約日` = '2024-01-07' AND `顧客`.`ID` IN (1, 2, 3, ..., 50)
そして、プリセットデータを作り直した際に検索ロジックが変わることに関してですが、プリセット自体は1ヶ月以上前に作っていました。 顧客が属するスマートリストを返すロジックも実装済みで、1ヶ月間以上エラーの発生がなく動いていました。
その状況で、パラメータの書き換え作業を行うのですが、初回予約の顧客 は 初回予約の顧客 、 要フォロー顧客 は 要フォロー顧客 のままなので、大きな変更を加えている認識なく作業を行なっていました。

しかし、実際には検索パラメータが変わっているので、検索クエリが切り替わってしまいました。 その結果、殆どのテナントは数秒以内にレスポンスを返せていましたが、特定のテナントでは1クエリが20分以上もDBのプロセスを保持してしまう状況になり、サーバーが詰まってしまい障害に至ってしまいました。

見逃した点
今回は、DBの実行計画も確認し、実際にデータを作成し、動作確認も行なっていたのに関わらず、障害に至ってしまいました。 また、DBの監視を行なっていたのに関わらず、原因の特定が遅れてしまいました。
DBの実行計画確認時の見逃し
先に述べた様に、今回のロジック変更時にEXPLAINでDBの実行計画を確認していました。
確認した結果、インデックスが使われて、数万分の1程度に絞り込めていました。
そのため、問題なしと判断しましたが、STORES 予約はマルチテナントな環境なので、テナントが1万もあればテナントを絞り込むだけで `テナント`.`ID` のインデックスで1万分の1に絞り込めてしまいます。
そのため、一見インデックスで大幅に絞り込めている様に見えて、実は結構なレコードを走査していることに気付くことができませんでした。
また、本来はインラインビューの内外それぞれで50件に絞り込めている必要がありますが、インラインビューの外側では、`顧客`.`ID` のインデックスにより、50件に絞り込まれた結果が表示されていたため、想定通りのインデックスが使われていると判断してしまいました。
EXPLAIN のイメージ ※ 実際にはもっと多くのテーブルをJOINしているし、もっと多くの情報が出ている。
| table | type | key | rows | filtered | extra | 補足 |
|---|---|---|---|---|---|---|
| 顧客 | range | PRIMARY | 50 | 0.1 | using index | 50件に絞られているので良さそう |
| 予約ページ | ref | テナントID | 10 | 100.0 | using index | indexが使われているし、次に使われる行数が100%で、件数的にも全件走査もしてなさそう |
| 顧客 | ref | テナントID | 1000 | 100.0 | using index | indexが使われているし、次に使われる行数が100%で、件数的にも全件走査もしてなさそう(keyをよく見ると絞りきれてない) |
| 予約 | ref | テナントID | 50 | 100.0 | using index | indexが使われているし、次に使われる行数が100%で、件数的にも全件走査もしてなさそう |
動作確認時の漏れ
今回も確認環境で、動作確認を行なっていましたが、両極端の環境でしか確認できていませんでした。
データがあり過ぎると検索結果が多くなり、正しい結果になっているか判断が難しくなります。 そのため、検証時には、分かりやすい様に最低限+α程度のデータで検証を行っていました。 また、タイムアウトの確認では、タイムアウトを発生させるためにあえて高負荷な状況を作って動作確認しました。
その結果、顧客の検索とスマートリストの合致の検索の2箇所とも通る確認と2箇所とも落ちる確認しかできていませんでした。 最初の検索は通るが、スマートリストの合致の検索は時間がかかるという状況で確認できれば障害を防げていたかも知れません。

監視先の漏れ
STORES 予約のデータベースは、負荷分散や耐障害性向上のために、読み書き両用のライターインスタンスと読み込み専用のリーダーインスタンスがあります。
スマートリストのデータ書き換え時には、DBのライターインスタンスのメトリクスを監視しながら作業を行なっていました。 今回障害が発生した箇所は、顧客の検索なのでリーダーインスタンスに向けてクエリを発火していました。
つまり、ライターインスタンスで書き込んだデータがWebアクセス時に読み込まれ、その値を使ってリーダーインスタンスにクエリを投げていたため、書き込み作業を行なっていたライターインスタンスの負荷は一切高くならず、異変に気づくのが遅れてしまいました。

ログの損失
STORES 予約では、Rails上のDBアクセス等のメトリクスはリクエスト処理の最後に集計先に送られる様になっていました。 最後まで処理しないと計測できない指標が多くあり、まとめて投げた方が効率が良いため、多くのアーキテクチャではその様な仕組みになっていることが多いと思います。
しかし、今回の障害の場合、DBへのリクエストが20分固まる状態になっていました。 そして、DBのレスポンスを待っている間に、リクエスト処理を行っているプロセスが固まったと判断され、メトリクスを投げる前に止められていました。 そのため、詰まってしまったリクエストのメトリクスを確認することができず、原因の特定に遅れてしまいました。

おわりに
というわけで、スマートリスト機能の開発の裏側で起きていた事例を紹介しました。
現在は、DB設計等から見直しを行いました。 なので、今回紹介したインラインビューを使ったロジックは現在行われていません。 また、見直した結果、元々の検索の速度も以前より速くなったりしています。
そして、障害が再発しない様に、このAPIのEXPLAINを確認して走査量が想定以上でないかを確認するテストが追加されていたり、該当ロジックの実測が行いやすい様な環境が整っています。
これらの設計の見直しや再発防止策を実施するために、スマートリストは5月のリリースまで遅れることになってしまいました。
最終的にどんな設計になったか、再発防止策について詳しく…については誰かがブログを書いてくれるかも知れません。
今回は急ぎすぎると結局スケジュールが遅れたり、障害が発生しユーザーにご迷惑をおかけしてしまった事例を紹介しました。 身の回りで似た様な事例があれば、スケジュールに無理がないか確認したり、急ぐとどの様な部分が漏れやすいのか、様々な人に迷惑をかけてしまうといった事例として参考にしてもらえればと思います。