

STORES 決済 でバックエンドエンジニアをしています id:nhayato です。
STORES Advent Calendar 2022 の 14 日目の記事です。
本エントリーでは、以下について紹介します。
- fastText / NDC Predictor を利用した図書の分類とその結果
- 職場内における図書管理のあり方について、私が考えていること
背景: 図書分野に関する個人的な関心
私は STORES に入社する以前より、図書、特に技術書についての職場内での扱いに関心がありました。 前職では図書委員のように、部署内の図書について、貸出管理システムの運用や購入依頼への対応、棚卸しなどの業務について関わっていました。 また、インターンシップ受入や新人研修のような教育の場で、たとえば、オブジェクト指向の説明を「図書管理システム」を題材に話すということもありました。 本業として「図書管理システム」の開発・運用に関わったことがないものの、自分のための題材として温めていたものになります。
コロナ禍以前は、職場での図書の貸出管理に関するエントリーが Web 上で公開されており、私は大変楽しく読んでいました。 しかし、最近はめっきり見なくなってしまい、少し悲しい。 そこで本エントリーでは、図書に関する話題を披露することにしました。
また「私が新しくライブラリを触る時、こういう感じで試してみてるよ〜」という紹介の側面もありますので、詳しい方には冗長な記述が多いですが、お付き合いいただければ幸いです。
課題: 図書の自動分類と fastText との出会い
皆さんは書店や図書館に訪れた時、どのようにして目当ての本を見つけますか。 ネット注文や事前予約で、受け取るだけという方も多いかもしれませんが、設置してある検索端末や地図などを利用してエリアを絞り込む、 あるいは馴染みの書店や図書館がある方であれば、「このエリアには、このジャンルの本があるよな〜」とあたりをつけて、移動されるでしょう。
図書の本棚への配置は、書店や図書館、またそこで働く方々のこだわりが感じられるところです。 書店・図書館ごとの差分もあるため興味深く、またよく考えられており、一人の利用者としてはありがたいものだなと思っています。 しかし、一人のエンジニアとしては、この分類をソフトウェアを使った課題解決と捉え、自動的にできる可能性も探ってみたいというモチベーションがありました。
前職での図書委員の活動の一環として、この「図書分類の自動化をしたい!」という課題を、機械学習の問題(教師あり学習の多クラス分類問題)として取り組んでいました。 その後、自動分類の取り組みからは少し距離をおいていたのですが、国立国会図書館という日本の最大級の図書館が、図書の自動分類のためのモデルを公開していたことを知りました。 この 1 つのファイル形式で保存されているモデルと fastText というソフトウェアと組み合わせて使うことで、書誌情報を入力すると、分類結果を出力できることができるようです。
いつか触ってみたいなと思いつつも、いつの間にか存在すら忘れてしまい……。 今回アドベントカレンダーにあたって、これらを触ってみたぞというエントリーを書いてみるか!というのが執筆の経緯となります。
紹介: fastText について
fastText について簡単に紹介すると、fastText で公開されているソフトウェア、または 2016 年に発表された論文中で紹介される、学習のアルゴリズムのことを指すようです。このソフトウェアを使うことで、任意のテキストを入力すると「このテキストは、○○ について書かれているよ」と教えてくれる仕組みを作ることができます。
検証: fastText のチュートリアル
私も公式のテキスト分類チュートリアルで fastText を使ったクラス分類に入門してみました。 Linux や macOS、または Windows の WSL のような UNIX ライクな環境での実施が想定されているようで、私は macOS を利用しました*1。 実行方法については端末エミュレータから実行できる実行ファイル形式と Python 形式の 2 種類が用意されています。
チュートリアルは、英語の QA サイトである Stack Exchange の料理ジャンルの投稿を題材に、各投稿に付与されたタグを、タイトルから自動で推定するという問題を解いています。 アノテーションデータが与えられた状態から、学習、検証、改善という流れを対話形式で進めることができます。 機械学習を初めて取り組む方にも理解しやすい内容で、 ズルをしないようなデータの分割や、Precision や Recall といった評価尺度の説明を知ることができます。
このチュートリアルで、私は「学習・分類に使うデータ形式は 1 行ごとなのね」「ラベルは__label__のように付与するのか」「入力文字列はトークン化して扱うのね」などを知ることが出来ました。
日本語の取り扱いについては、チュートリアルの範囲対象外のため、別に調査する必要があります。
紹介 2: NDC Predictor について
国立国会図書館の提供している NDC Predictor の紹介をします。
- 紹介ページ: NDC Predictor
- Web アプリケーション: NDC Predictor
- GitHub: ndl-lab/ndc_predictor
NDC Predictor は、タイトルや著者の情報を入力すると、図書館の分類で一般的に使われている日本十進分類法(NDC)に基づいた分類ができる Web アプリケーションです。 この分類法は、皆さんがお住まいの公立図書館でも採用されていることが多いのではないでしょうか。 本棚の側面に、"007", "400"のように 3 桁の数字を見たことがあるかもしれません。
Web アプリケーションでは、画面中のフォームに適当な文字列を入れると、上位 3 位までの候補が表示されます。 想定はタイトルや著者名のようですが、適当な文字列を入れても問題なく結果が出力されます*2。
Web アプリケーションの裏側では fastText が動いているようです。 チュートリアルでも学んだように、モデルと呼ばれるファイルを fastText と組み合わせることで、分類問題を解くことが出来るのですが、このモデルファイルは公開されているため、ローカルの環境でも分類を実施できます。
検証 2: ローカル環境で ndc_predictor を使った分類
GitHub の ndl-lab/ndc_predictor からダウンロードできるモデルを使って、ローカルでも NDC の分類を試してみます。 リポジトリの中には検証データも入っているため、簡単にモデルの検証まで試すことが出来ます。
手順
- ndl-lab/ndc_predictor README 内の、学習済み fastText モデルの項目からリンクされている、NDC 3 桁のモデルをダウンロードし展開*3
- テストデータをndl-lab/ndc_predictorよりダウンロードし、展開
- (ビルド済みの)fasttext 実行ファイルを、モデルとテストデータを指定し、実行
$ cd fastText $ wget https://lab.ndl.go.jp/dataset/ndc/model/model_ndc3.bin.gz $ gzip -d model_ndc3.bin.gz $ git clone https://github.com/ndl-lab/ndc_predictor.git $ cp ndc_predictor/test/test_ndc3.txt.gz . $ gzip -d test_ndc3.txt.gz $ ./fasttext test model_ndc3.bin test_ndc3.txt N 149468 P@1 0.753 R@1 0.753
最後のコマンドでモデルの評価を行っています。
README に記載されている Recall(R@1) 0.753 と結果は同じになりました。
ついでに、検証データの構造も探っておきます。 どのような入力を想定しているのか、どのような前処理をしているかなどを探るために有用です。
% head -n 5 test_ndc3.txt __label__532 機械 製作 法 通論 . 下 / 東京大学 基礎工学 双書 東京大学出版会 , 千々岩 健児 編著 ; 長尾高明 , 木内学 , 畑村洋太郎 著 . __label__467 生きもの 上陸 大 作戦 絶滅 と 進化 の 5億 年 / 社会福祉法人日本ライトハウス 情報 文化センター ( 手製 ), 中村桂子 , 板橋涼子 著 . __label__377 博士 学位論文 内容 の 要旨 及び 審査結果 の 要旨 . 第 27 集 . 奈良県立医科大学 , __label__301 社会 を 読み とく 数理 トレーニング : 計量 社会科学 入門 / 東京大学出版会 , 松原望 著 . __label__338 資金 移動 業 の しおり : 資金決済に関する法律 / 第 4 版 . 日本 資金 決済 業 協会 , 日本 資金 決済 業 協会
NDC の分類情報の数字はそのまま __label__532 のように書かれていますね。
実験: 自前の書籍データを使った ndc_predictor を使った分類
「リポジトリ内のテストデータで動かしてみた」だけでは面白くないので、自分の持っているデータでも試してみます。 私は ブクログ というサービスを使って蔵書や閲覧の記録をしているのですが、こちらには CSV ファイルでエクスポート機能が提供されているため、このデータを利用します。
ブクログには、新しく書籍を登録するときに、ユーザーが任意のカテゴリ名を本に対して付与する機能があります。 私は技術書には IT カテゴリを付与しているため(他には漫画や小説などのカテゴリを付与しています)、この IT の図書一覧だけ取り出して、自分の付けた分類と対応しているかチェック してみます*4。 対象となる IT カテゴリの図書の総数は、523 件でした。
実施した処理ですが、以下の二段構成にしました。
形態素解析パート
まず、形態素解析パートから。 fastText の入力はトークンが求められているという話を書きました。 英語であれば語と語の間にスペースが含まれているため、*5そのままでの入力も可能そうですが、日本語は前処理としてわかちの処理をする必要があります。
形態素解析器を使ったわかち書きの例を以下の図で示します。
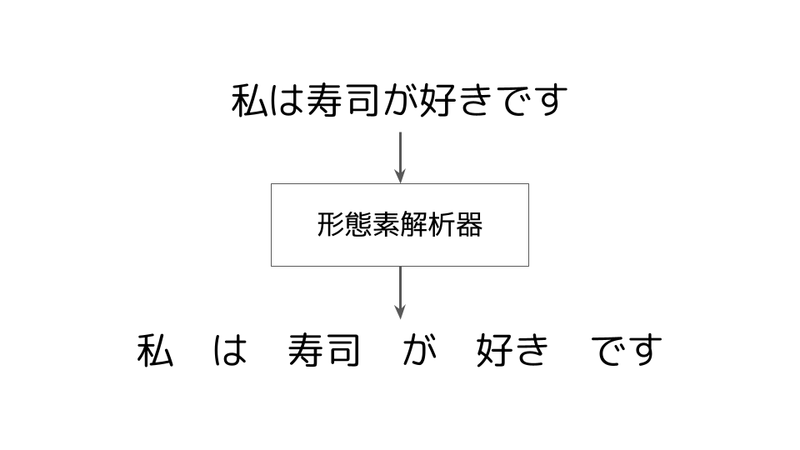
形態素解析器を使うことで、このようにまとまった単位をスペースで区切るテキスト処理が実施できます。
ndc_predictor は形態素解析器として Kuromoji でわかち書きされた入力を想定しています。
モデルを作成した学習データへの前処理と検証データの前処理は、差分がないほうが好ましいため、同じように Kuromoji を利用します。
私は、Kuromoji を使った形態素解析は初めてのため、具体的にどのような環境構築をすべきか勝手が少々わからなかったものの、リポジトリ内に記述されている概要やサンプルコードからあたりをつけて、codelibs/elasticsearch-analysis-kuromoji-ipadic-neologd を利用しました。
ライブラリの情報をpom.xmlに記載し、Maven を使ってインストールしました。
以下のコードは、ndc_predictor の README に書かれているコードを、CSV の読み書きに対応させたものです。*6
// import snip public class MorphologicalAnalyserCSV { public static void main(String[] args) throws Exception { List<String[]> output = new ArrayList<>(); List<String[]> input; try (CSVReader reader = new CSVReaderBuilder(new FileReader("./booklog-utf8.csv")).build()) { input = reader.readAll(); } for (String[] elems : input) { var genre = elems[3]; var title = elems[11]; var author = elems[12]; var publisher = elems[13]; List<String> titleTokens = new ArrayList<>(); if (genre.equals("IT")) { try (JapaneseTokenizer tokenizer_a = new JapaneseTokenizer(null, false, JapaneseTokenizer.Mode.SEARCH)) { tokenizer_a.setReader(new StringReader(title)); CharTermAttribute term = tokenizer_a.addAttribute(CharTermAttribute.class); tokenizer_a.reset(); while (tokenizer_a.incrementToken()) { titleTokens.add(term.toString()); } var parsedTitle = String.join(" ", titleTokens); String[] row = new String[]{title, author, publisher, parsedTitle}; output.add(row); } } } try (ICSVWriter writer = new CSVWriterBuilder(new FileWriter("parsed.csv")).build()) { writer.writeAll(output); } } }
テストデータが公開されているタイトルと出版社と著者の情報を利用しているようですが、具体的な前処理の詳しい流れについては読み取れなかったため、今回はタイトルのみを分類に利用しました。 ただしタイトルはブクログでのタイトル情報を利用しており、学習に利用した入力形式とは異なると思われます。 例えば、括弧内に出版社の情報やシリーズ情報などが含まれています。 fastText のチュートリアルにもあるように、括弧や記号などの約物は、前処理・正規化を実施することで、精度向上にも寄与すると思われます。
fastText パート
次に、fastText パートです。 今回は端末エミュレータからの実行ではなく、Python を使いました。 慣れた環境ということで、ローカルの端末上で venv で開発環境を作って pandas や Jupyter Notebookなどのモジュールをインストールしています。 また、今回は利用しませんでしたが、Google Colab を使うとローカルのセットアップなく、ブラウザ上から Python を使うことができるため、セットアップに悩みたくない方や、環境を汚したくない方などはこちらを使ってみることをオススメします*7。
>>> import fasttext >>> import pandas as pd >>> data = pd.read_csv("./parsed.csv",header=None) >>> model = fasttext.load_model("./fastText/model_ndc3.bin") >>> for row in data.itertuples(): ans = model.predict(row[4]) ndc = ans[0][0][-3:] print(row[1], ndc, ans[1][0]) エキスパートCプログラミング—知られざるCの深層 (Ascii books) 007 0.9856999516487122 # (以下省略)
上記は、CSV ファイルを読み、fastText に処理をさせて、結果を得るというコードです。 先頭行の『エキスパート C プログラミング』という書籍は、 007(情報科学)であるという出力を得ることができました。 これは正しく分類できてそうです。 結果はこれ以降も続きますが、その先のデータに対しても、途中でエラーを吐くことなく結果を出力しています。
実験結果
さて、ここからは自分の付けた分類と対応しているかチェック してみましょう。 情報分野ではないと分類された出力*8に対して、目で確認をしてみます。
私が IT と分類した書籍が 523 件あり、そのうち 234 件が情報の書籍ではないと fastText は判定しました。 この件数をもって fastText やモデルの性能を論じることはできませんが、今回の用途であれば、もう少し情報分野の書籍であると判定してほしかった。
実際に「情報分野ではない」の出力結果を眺めてみると、
| id | タイトル | fastText 出力 NDC |
|---|---|---|
| 1 | A 子さんの恋人 7 巻 (HARTA COMIX) | 726(漫画) |
| 2 | カレー、スープ、煮込み。うまさ格上げ おうちごはん革命 スパイス&ハーブだけで、プロの味に大変身! | 596(食品.料理) |
と 726(漫画)や 596(食品.料理)のように誤って私が IT と分類した書籍を見つけることができました。
しかし、上記のようなケースは稀で、多くは情報分野の書籍として分類してほしい書籍を、別のクラスとして分類しています。 以下は、興味深い結果の抜粋ですが、
| id | タイトル | fastText 出力 NDC |
|---|---|---|
| 3 | プログラミングコンテストチャレンジブック | 798(室内娯楽) |
| 4 | Lean と DevOps の科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する (impress top gear) | 336(経営管理) |
| 5 | 人月の神話—狼人間を撃つ銀の弾はない (Professional Computing Series 別巻 3) | 913(小説.物語) |
| 6 | ユニコーン企業のひみつ | 686(鉄道) |
| 7 | 推薦システム実践入門 | 279(社会教育) |
id=3のように、言われてみればプログラミングは室内娯楽という側面もある気がしてきますが、
こちらに本来分類される書籍は、トランプカードやかるたのような遊びに関するもののようです。
またid=4も、経営管理の書籍としても違和感はなさそうですが、まだ IT の技術書として取り扱う余地も残しておいてほしい。
id=5は IT の業界では有名な「銀の弾丸はない」という用語を広めた書籍ですが、
よくよく考えてみるとタイトルだけでは情報分野の書籍には見えない。
人間でもこれらの単語を知らなければ、情報分野の書籍として扱うことは難しいでしょう。
id=6やid=7はそれぞれ「どうしてそこに」という結果ですが、この分類の書籍ではこのような単語を含むタイトルが多いのかもしれません。
注意事項
さて、サンプルを試してみて、自前のデータでも分類器が動くことを確認できました。 カテゴリ分類の差分を発見できたので収穫は(一応)ありました。
注意事項として、この実験は leak している可能性があります。 つまり、学習に使った図書データを評価にも使っているというケースです。 モデルの検証として厳密に実験したい場合は、モデルが作られたあとの出版日の図書データだけを評価に利用するというアプローチが必要です。
また繰り返しにはなりますが、学習時と評価時に使ったデータの形式や前処理は合わせる必要があります。 学習時は、タイトルだけでなく著者や出版社の情報を入力として使っていたようです。 しかし、自前のデータでの実験では、タイトルのみを入力としてしており、 また、タイトルと著者の間にある記号や、著者名のあとにある「著」などの挿入も行っていません。 モデルを利用していておこがましいことは承知ですが、実験に使ったデータの取得方法や前処理のソースコードも公開していただけるとありがたいな〜と感じます。
考察: 職場への技術適用について
さて、STORES 社内にもライブラリコーナーがあり、本棚が設置されています。 技術書だけでなく、デザインの本やビジネスの本、漫画などもあり、なかなかバリエーションが豊富です。 大きくジャンル分けはされているものの、ジャンル内はわりと大雑把に並べられていたため、 ここまで試してみた自動分類の仕組みを使えそうな気がしましたが、はたして利用可能でしょうか。
結論から言うと、現状では適用するのは少し慎重になったほうが良さそうです。 そもそも今後出版される書籍の多くは NDC が付与されているでしょうから、国立国会図書館の公開している書誌情報など、外部情報を取得する方法が確実で簡単でしょう。 やりたいタスクに対して、機械学習で対応すべきかどうかは、しっかり考えたほうがよさそうです。
観点 1: さらに細かい分類法の検討
しかし、既存の分類で十分なのかという観点はあります。 つまり 3 桁で表現されている NDC 3 次区分の粒度でよいのか。 例えば STORES には技術書がありますが、多くは情報分野に関するものです。007(情報科学)や 547(電気通信)548(情報工学)に分類されるわけで、これだと大雑把すぎる。
プログラミング言語関連の書籍を題材に説明します。 STORES 決済 は 1 つのプログラミング言語で作られているわけではなく、サーバーサイドは Java、モバイルは Swift 、フロントエンドは......というように、複数の言語を利用しています。 さらに、この技術スタックはプロダクトごとに異なりますから、言語の種類はもっと多い。 言語ごとに書籍があると仮定して、書籍利用者のことを考えると、複数のプログラミング言語の書籍が乱雑に配置されているよりは、言語ごとに配置されていたほうが探しやすいかもしれません。
これはプログラミング言語に限らず、職場に見合った粒度で書籍が整理されていることが、利便性の向上に影響しそう*9。 細かい粒度の分類器の実現は現状のデータだけでは対応できないため、細かい分類法(クラス)を設計し、追加でデータに対してアノテーションを実施する。 そうして、新しいデータから新たな分類器を作ることで、新たなクラス分類に対応できます *10 。
観点 2: ツールを実運用・書籍管理のコストの検討
また、観点 1 がクリアになったとして、分類器を備える図書管理システムを運用するとなった場合でも、 非技術的な観点として、環境の変化について考える必要があります。 コロナ禍において、毎日出社することはなくなってしまったため、書籍が職場にあることのメリットは以前より下がってしまったかもしれません。 物理書籍というフォーマットではなく電子書籍を購入することも増え、公式のチュートリアルや Blog 記事などの Web サイトで十分という考え方もあります。 英文で書かれた情報の読解についても、英語が苦手でも機械翻訳サイトのおかげで、以前よりも簡単に読みすすめることができるようになったことが書籍の優先度を下げているのかもしれません。
出社の頻度やチームのスキルレベル、抱えている課題など、さまざまなパラメータがあるなか、社内に技術書があるおかげで、助かった!となることはあるかもしれません。 しかし、しっかり図書を管理するよりも、もっと他のことにリソースをつぎ込むほうが、組織全体としては嬉しいという考え方もあります。
このような背景から、職場に技術書があるという状態がどの程度であるべきなのか、というのは、実は「自分たちの職場をどのような場にしたいか?」「どのように職場で過ごしたいか?」という話と地続きと私は考えています。 どの会社にも当てはまるような完全な正解があるわけではなさそう。このあたりは STORES のいろんなメンバーと話をしてみたい気もしますね。
結論
本エントリーでは、まず図書分類タスクについて紹介、fastText のチュートリアルを実施、学習済みモデル ndc_predictor の検証や自前のデータでの実験結果を紹介しました。
また、自動分類の仕組みが職場利用の可能性の検討や、職場での図書の扱われ方に関する考察をしました。
このように、すぐには使わないツールでも、現状の挙動確認をしておくことで、ちょっとした困りごとを、既存の技術で解決可能かどうかのあたりをつけることができます。 また、取り組む上での問題点について知ることができます。
ちなみにここまでの作業時間ですが、執筆時間を除くと、 1 日から 2 日程度の時間で実施しました。 私は初めて使うソフトウェアもあったため時間がかかってしまったところもありますが、 今後似たようなタスクに取り組み場合は、もっと素早くできることが期待できます。
今回はアドベントカレンダー執筆をきっかけに、これまで気になっていたけれど手を出してこなかったツールについて、使ってみたという記事をまとめてみました。今回は図書分類に関する話題でしたが、様々な学習済みモデルが Web 上には公開されているようなので、自分が気になる問題を 「fastText を使って自動化できるかも」と Just for Fun のきっかけにしていただければ幸いです。
参考文献
*1:ちなみに Apple シリコンの環境のため、2022 年 12 月現在は、この Issueで紹介されている Makefile 内のビルドオプションの修正が必要でした。
*2:ところで、クリックすると入力されるサンプルの中に『「舞姫」の主人公をバンカラとアフリカ人がボコボコにする最高の小説の世界が明治に存在したので 20 万字くらいかけて紹介する本』があるところに、アプリケーション制作者のユーモアを感じますね。
*3:ただし NDC1 についてのデータは、Access Denied となりダウンロードができませんでした。
*4:データ自体の公開は恥ずかしいので、ここでは結果だけお見せします。
*5:複合語の処理など考えることはあるものの
*6:CSV ファイルを読み込むために opencsv というライブラリを利用しました。
*7:Web 上にも解説記事が多いです。
*8:007(情報科学)、547(電気通信)、548(情報工学)以外と分類された出力
*9:大学図書館のような専門書が多い環境の場合、情報分野の書籍については、さらに細分化した独自分類を採用するという図書館もありますが、以前調査した時には、一般的に使われている分類法を見つけることはできませんでした。
*10:NDC には 007.13 のように更に細かい分類もあるため、そちらを使うことも検討事項となります