
こんにちは、データ本部のssxotaです。STORES でデータエンジニアをやっています。
STORES のデータ基盤では、2025年7月からデータ転送ツールである TROCCO を導入しました。
今回のブログでは、TROCCO導入の背景、ツール選定の理由、活用事例について紹介します。
なぜTROCCOを導入したのか?
SaaS間のデータ連携におけるデータエンジニアの工数削減
これまでは、各SaaS間のデータ連携について、SaaS側で提供されているAPIに対してPythonやRubyでスクリプトを実装し、ワークフローエンジンとして採用しているArgo Workflows上にポーティングして実行していましたが、これらの構成では、
- 既存項目の追加・削除に伴うソースコードの修正
- SaaS側APIの仕様変更への追従
- コンテナ上で使用しているライブラリの脆弱性に対するメンテナンス
といった、保守作業のコストが継続的に発生していました。
新しいSaaS製品のデータ取り込み要望が出た場合にも、API仕様の調査、スクリプトの実装・テストといった工程が必要となり、データが利用可能になるまでに一定のリードタイムがかかっていました。
このような、データエンジニアの作業がボトルネックになり、データが利用できる状態になるまでに時間がかかる状況を改善したかったこと、SaaSからのデータ取得などの基本的な処理にエンジニアリングリソースを割くのではなく、AI活用に向けたデータ整備やモデリング改善など、より重要なデータ活用推進の施策に時間を割ける状態を目指し、データ転送ツールの導入を検討しました。
ビジネス部門のデータ活用の効率化
セールス部門やBPR部門などのビジネス部門では、SalesforceやkintoneをはじめとしたSaaS製品を日々のセールス活動や業務オペレーションで活用しています。
具体的には
- SalesforceのオブジェクトやレポートをGoogleスプレッドシートに出力し、スプレッドシート上でモニタリング
- スプレッドシートで管理しているデータをGASでkintoneへインポート
といった、SaaSとスプレッドシート間の連携が広く行われていました。
BPR部門では生成AIを活用してGASを開発するなど、社内のエンジニアリングリソースに依存せずに積極的に業務改善が進められています。
一方で、GASの開発・保守にも一定の工数が発生しているため、TROCCOのような転送ツールを活用することで、そもそもGASの開発が不要となり、一定の工数削減が見込めると考えました。
Salesforceからのデータ転送については、Google提供のコネクタでは転送可能なデータ量の制限があり、データ量の多いオブジェクトのデータに関しては、BigQueryに一度データ連携したうえで、コネクテッドシートでスプレッドシート側に取り出すといった対応も行われており、データエンジニアの作業を必要とする状況でした。
また、これらのデータ転送処理の管理は、各チームや担当者毎の管理となっており、組織内や一定のツール上での一元管理がされておらず、どこで,どのような転送処理が動いているのかが把握しづらい状態でした。
データ転送ツールを導入することで、ビジネス部門におけるデータ転送処理の効率化を図るとともに、ツール上で実現できるデータ連携に関してはツール上で集約管理することで、ガバナンス強化を実現できるのではないか、という狙いがありました。
選定にあたって
ツール選定にあたっては、Fivetranなどのデータ転送ツールも候補に挙がりました。
その中でTROCCOを選択した理由としては
- ビジネス部門での利用も想定していたため、日本語主体で非エンジニアでも理解しやすいGUIであること
- STORES で利用している国内SaaS向けのコネクタが充実していること
- SaaS側からのデータ転送だけでなく、リバースETLといったSaaS側へのデータ追加/更新が標準機能として提供されていること
といった点が大きく、最終的な採用の決め手となりました。
TROCCO導入後
こちらがTROCCO導入後のデータ基盤の概要図です。
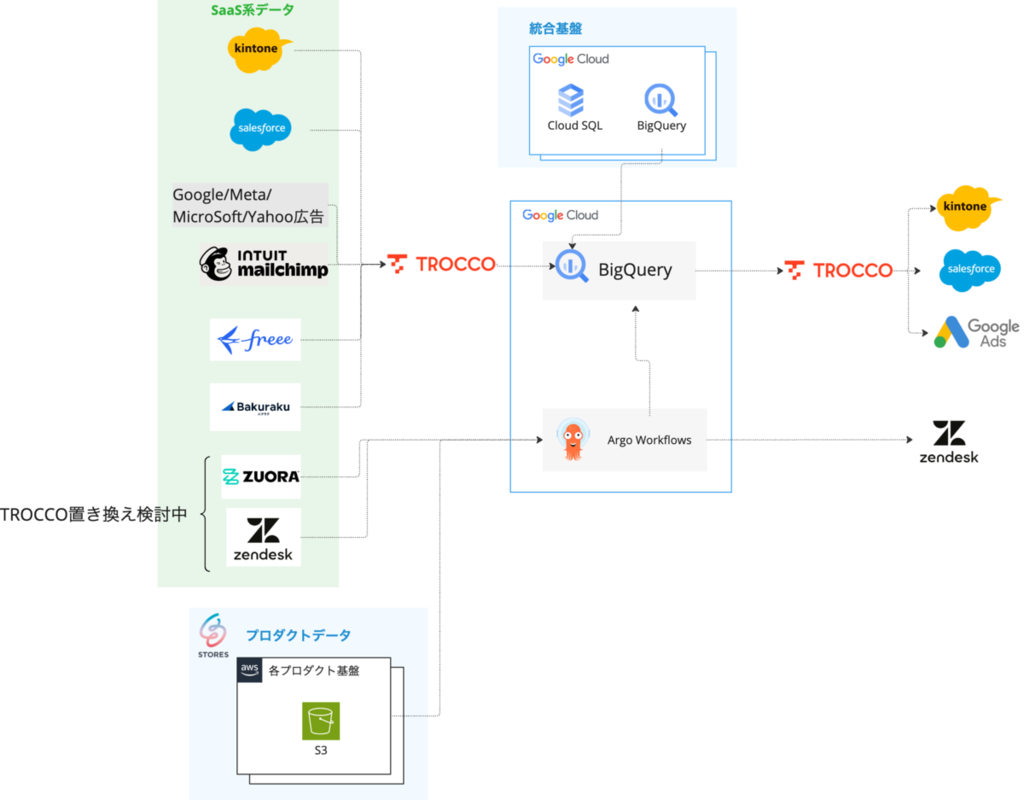
各SaaS間連携
SaaS間の連携に関しては基本的にはTROCCOに置き換える方針で移行作業を進めています。
Salesforceに関しては今年度社内でCRM/SFA統合プロジェクトが発足し、既存の複数のCRM環境を統合した新しいSalesforce環境が構築されました。 この新環境からのデータ転送をTROCCOのマネージド転送機能を用いてBigQueryに連携することで、ソース引き込みの工数が圧倒的に短縮でき(1〜2日程度)、既存環境で構築されていたモニタリング基盤をスピーディに新環境へ置き換えることができました。
kintoneに関しては、kintoneからのデータ転送だけでなく、収集したデータをBigQueryに連携し、プロダクトデータと組み合わせたうえでkintoneへ差し戻すリバースETLの処理も、すべてTROCCOに置き換えが完了しています。
マーケティング部門で利用するGoogle/Meta等の広告プラットフォームとの連携や、Mailchimpといったメルマガ配信に関しても、TROCCOで対応しています。
このほか、コーポレート部門の集計用途として、freee / バクラクの新規データ取り込み要件がありましたが、こちらもTROCCOで対応しました。 これらのデータは秘匿性が高く、利用者以外による閲覧を禁止する必要があるため、BigQuery側での閲覧制限に加えて、TROCCOのチーム機能を活用し、データ転送処理自体の操作権限も限定しています。
一部、ZendeskやZuoraに関しては置き換えが完了していませんが、Zuora等の標準コネクタでの対応がないSaaSに関しても、カスタムコネクタ機能による対応が可能なため、移行検討を進めていく予定です。
既存のワークフローエンジンとの使い分け
TROCCOはAuroraやCloud SQLなどのDB製品からのデータ転送にも対応していますが、現時点ではすべてのデータ転送をTROCCOに置き換える予定ではありません。
各プロダクトからの日次データ転送については、事業者様向けのデータ分析機能にも利用されており、社外への影響も大きい処理です。 そのため、プロダクト由来のデータ転送については、引き続きArgo Workflows上で実行し、STORES 内で品質を管理できる構成を維持しています。
一方で、SaaS間のデータ連携や仕様変更や新規追加に対しては、TROCCOを活用することで、品質を担保しつつ、 データ利用までのスピード感を落とさない運用ができるよう、既存のワークフローエンジンとTROCCOの棲み分けを意識しながら運用をしています。
ビジネス部門への導入
ビジネス部門へのTROCCO導入にあたっては、TROCCOの開発販売会社であるPrimeNumber様にご協力いただき、Salesforceおよびkintoneを題材としたレクチャー会をビジネス部門向けに開催していただきました。
主にスプレッドシートとの連携を題材にレクチャーを実施しましたが、これまでのスプレッドシートでのデータ量に伴う連携に関する課題への質問や、GASで実行している処理を代替できないのかといった、実際の利用に踏み込んだ質問もいただき、参加者の方々が興味を持ってレクチャー会に参加いただけていました。
ビジネス部門での導入は、まだまだ始まったばかりで、現状は一部社内ユーザーの利用に限定されていますが、利用頻度の高い連携パターンに関しては、テンプレートを展開するなど初回の転送のハードルを下げる対応や、事例の共有等を通して、ビジネス部門での利用を促進していく取り組みを進めていきたいです。
また、レクチャー会での質疑を通して、データ本部として把握していなかったGASの利用方法もあり、ビジネス部門内で行われている業務に対する深掘りも、データ連携に伴う課題を本質的に解消するうえでは継続的に必要であることも実感しました。
まとめ
データ基盤の立ち上げ時や、データエンジニアが不在の環境下で分析環境を用意する目的で、TROCCOを導入されるケースも多いかと思います。今回は、すでにデータ基盤が存在する中で、課題を解消する手段としてTROCCOを採用した事例を紹介しました。
導入後は、SaaS間の引き込みに関して、新規のデータ連携の案件に対しても工数の余裕を持って対応できるようになりました。
今回のビジネス部門への展開も一例ではありますが、データエンジニアの業務領域が、データ基盤のシステム的な保守運用から、業務オペレーション等の社内のデータの流れの整備へシフトしているのも肌で感じています。
今後もデータ基盤の運用をできるだけ省力化しつつ、よりデータ活用が促進するための整備や、業務オペレーションの改善に取り組んでいきたいと考えています。
STORES では積極的にデータエンジニアの採用活動を行っております。
カジュアル面談も実施しておりますので、ぜひお気軽にご応募ください。