

STORES でエンジニアをしている片桐です。
先日、「Goで作られたシステムをRuby on Railsに移植しています」というブログを投稿させていただきました。
ベース部分の実装について別ブログで紹介したいと書かせていただきましたが、今回はその中から「複数データベースの設定」について紹介させていただきます。
作業の全体像
移植先のシステムから移植元のシステムのデータベースを扱えるようにするに当たって、行わなければならない作業は大きく3つありました。
- 移植先システムから移植元システムのデータベースにアクセスできるようにインフラ構成を変更する。
- 移植先システムに移植元システムのデータベースに接続するための実装を入れる。
- database migrationを移植先システムから行えるようにする。
ここからは、上記の3つの作業について具体的に紹介していきます。
以降、記事中で例示するプログラムのコードの各所に「maja」という単語が出てきますが、これは移植元のプロダクト名です。
インフラ構成の変更
移植元のシステムも移植先のシステムも、インフラにはGoogle Cloudを使用しています。しかし、2つのシステムは別々のprojectに所属しているのでそのままでは移植先のシステムから移植元のシステムのデータベースにアクセスできません。
私自身はGoogle Cloudにおける運用の経験があまりなく、接続方法についての知見もなかったので、まずはそこを調べるところから始めました。
private IP接続とpublic IP接続
下記の資料のとおり、Cloud SQLへの接続方法にはさまざまなオプションがあります。
データベースへの別projectからのアクセスを可能にする一番かんたんな方法は、public IPを設定し、インターネットからアクセス可能にすることです。しかしながら、public IPを設定することは公開インターネットからのアクセスが可能になることを意味するので、攻撃ベクトルが増えることになります1。また公開インターネットを経由することによるレイテンシーの増加も発生します。
そのため、今回は技術的に不可能でない限りはprivate IPでの接続を目指すことにしました。
private IPでの接続方法
早速private IPでの接続方法を模索していくのですが、実はGoogle Cloudにおいてはprivate IPでの接続自体に前提知識が必要になります。
AWSでは、RDSのインスタンスはユーザーの指定したVPCに存在します。なので、サーバープロセスと同じVPCにインスタンスを配置すれば、特に難しいことはなく普通に接続できます。それに対して、Google CloudではCloud SQLのインスタンス作成時にVPCを指定できません。ではこのインスタンスがどこに存在するのかというと「Google側が管理する個別のVPC」に存在しています。つまり、サーバープロセスが存在するVPCとは別のVPCに存在しているのです。そのため、何も設定していない状態だと直接Cloud SQLのインスタンスにはアクセスできません。
private IPを利用して普通に(= 同じproject内から)接続する場合は、Private Service Accessの設定が必要になります。
これはVPC ネットワーク ピアリングを利用して、サーバープロセスの存在するVPCのCloud SQLの存在するVPCを接続する機能です。これにより、双方のプロセス・インスタンスが同じVPCに所属しているかのような状態になるので、アクセスが可能になります。
projectを跨いで接続する
同じproject内で接続する場合はこれで良いのですが、Cloud SQLのPrivate Service Accessでは別ProjectのVPCからはアクセスできないようでした2。
先ほど紹介したCloud SQLへの接続方法のドキュメントを見ると、private IPでの接続にはもう1つ、「Private Service Connect」というオプションが提示されています。
上記のドキュメントの冒頭で、このオプションを利用する目的として以下の内容が記載されています。
異なるグループ、チーム、プロジェクト、組織に属する複数の VPC ネットワークから Cloud SQL インスタンスに接続する
これはまさに私が求めていた機能そのものです。この機能を利用すれば、統合先のシステムから統合元のデータベースにインターネットを経由せずに接続できそうです。
Private Service Connect の仕組み
Private Service Connect は複数の要素から構成されています。
- Service attachment (統合元のproject = databaseのあるprojectに作成)
- Private Service Connect Endpoint (統合先のproject = サーバープロセスのあるprojectに作成)
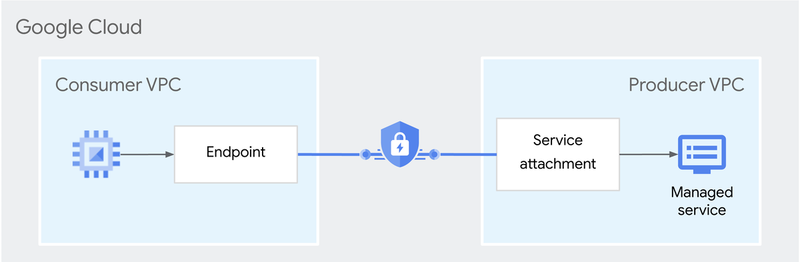
まず外部からの接続を受け付けたいCloud SQLに、Service attachmentが必要です。Cloud SQLの場合、インスタンスの設定として「Private Service Connectの有効化」という設定項目があります。そのため、個別に「Service attachment」というリソースを作成する必要はなく、この設定を有効にすることで自動的にService attchmentが作成されます。
それから、接続元になるproject(= 統合先のproject = サーバープロセスのあるproject)に「Private Service Connect Endpoint」が必要です。これの実態は、VPC内で利用できる「内部IPアドレス」と「内部IPアドレスとService attchmentを紐づけるForwarding rule」のセットです3。
この「Private Service Connect Endpoint」(図では単に「Endpoint」)のIPアドレスにアクセスすることで、別projectのリソースにアクセスできます。
ちなみに「Service attachment」には、「どのprojectからの接続を受け付けるか」という設定項目があります。ここで許可されたprojectにのみ「Forwarding rule」が設定できます4。
Private Service Connect の注意点
Private Service Connectには、下記のとおりさまざまな制限があります。
幸い、今回のユースケースで問題になりそうな制約はありませんでした。しかしPrivate Service Connectの制限は結構な数あるので、利用される際は制限事項にひととおり目を通された方が良さそうです。
また、重要な注意事項として、「Cloud SQLでService attachmentを有効化する際にはダウンタイムが発生する」というものがあります。既存のインスタンスにPrivate Service Connectの設定を追加する場合はご注意ください。
Private Service Connect を構成する
弊社ではインフラの管理にterraformを使用していますので、hclファイルにて構成を変更します。
移植元システム
modules/sql/variables.tf
# (略) variable "allowed_consumer_projects" { description = "Private Service Connect経由で接続を許可するprojectのリスト" type = list(string) }
modules/sql/main.tf
resource "google_sql_database_instance" "sql_database_instance" { # (略) ip_configuration { # (略) psc_config { psc_enabled = true allowed_consumer_projects = var.allowed_consumer_projects } } } # (略)
移植先システム
modules/network/variables.tf
# (略) variable "maja_cloud_sql_psc_service_attachment_link" { description = "MajaのCloud SQLのPrivate Service Connectで接続するためのリンク" type = string }
modules/network/main.tf
# (略) resource "google_compute_address" "maja_cloud_sql_psc" { name = "maja-cloud-sql-psc" region = var.region address_type = "INTERNAL" subnetwork = google_compute_subnetwork.bongo_01.self_link } resource "google_compute_forwarding_rule" "maja_cloud_sql_psc" { name = "maja-cloud-sql-psc" region = var.region network = google_compute_network.bongo.self_link ip_address = google_compute_address.maja_cloud_sql_psc.self_link load_balancing_scheme = "" # 無指定(nil)と同値ではないので注意 target = var.maja_cloud_sql_psc_service_attachment_link }
ほぼ下記のドキュメントのterraformの記載例そのままではあるのですが、当初はPrivate Service Connectの概念自体の理解に手間取っていました。そのため、どのリソースをどちらのprojectに作ればいいのか、それぞれのリソースが何を意味しているのかがわからず、かなり試行錯誤をしてこの形に落ち着きました。
これらのシステムを移植元、移植先の順に実際に反映していきます。
移植元でのPrivate Service Connectの有効化の方はダウンタイムがあるためタイミングの調整などを行いましたがそれ以外に特に難しいところはなく、無事移植先のprojectから接続できるようになりました5。
移植先システムにデータベースへの接続設定を入れる
この作業については特段難しい点はありませんでした。Ruby on Railsの複数データベースの設定方法に従ってコードを記述し、接続先情報を環境変数に設定するだけであっさりと接続できました。
config/database.yml
default: &default # (既存の設定なので略) maja_default: &maja_default adapter: postgresql encoding: unicode pool: <%= ENV.fetch("DB_POOL_SIZE") { 5 } %> database: <%= ENV['MAJA_DATABASE_NAME'] %> username: <%= ENV['MAJA_DATABASE_USER'] %> password: <%= ENV['MAJA_DATABASE_PASSWORD'] %> host: <%= ENV['MAJA_DATABASE_HOST'] %> migrations_paths: db/maja_migrate development: # (既存の設定なので略) maja: <<: *maja_default database: maja_development test: # (既存の設定なので略) maja: <<: *maja_default database: maja_test production: # (既存の設定なので略) maja: <<: *maja_default
app/models/maja/application_record.rb
Add commentMore actions module Maja class ApplicationRecord < ::ApplicationRecord self.abstract_class = true connects_to database: {writing: :maja, reading: :maja} end end
この辺り、Ruby on Railsは本当によくできているなと感心しました。
database migrationを移行する
viewとtrigger
Ruby on RailsのActiveRecordは表現力が非常に豊かです。そのためデータベースのviewやtriggerに相当する機能もActiveRecordを用いてシンプルな記述で実現できます。このやり方ではロジックの大部分がRubyのコードで記述できるので、ロジックが分散せず、読みやすいRubyのコード6でロジックを理解できるというメリットがあります。もちろんパフォーマンスや安全性などを考慮した場合にはデータベース側の機能を利用するべき場面もありますが、大抵の用途ではRubyでロジックを記述できるというメリットが勝る場面が多いと思います。
このような状況のためか、Ruby on Railsのmigrationはviewやtriggerといったものの定義を管理する機能を持ち合わせていません。 一方、移植元のシステムはGoで実装されており、ActiveRecordほどGoのコードでロジックを記述するメリットがなかったので、viewやtriggerを活用するような実装になっていました。
そのため、viewやtriggerをどう扱うかを考える必要がありましたが、以下の背景から今回の移植ではview・triggerは廃止していく方針にしました。
- 現時点で設定されているview・triggerのほとんどがActiveRecordで簡潔に代替できる。
- view・triggerで実現されているロジックをActiveRecordのコールバックやscopeを用いて置き換える対応を入れても、移植の難易度・工数に大きな影響は無い。
- Ruby on Railsにおいてはview・triggerを扱わない方が一般的なので、パフォーマンスなどで懸念が無いのであれば一般的なやり方に則りたい。
migrationでview・triggerを扱う
先述のとおり移植後はview・triggerを扱わない方針に決めましたが、それはそれとして現在のdatabaseにはviewもtriggerも定義されています。特にtriggerは、当然のことながら移植先システムからのSQLに対してもtirggerされます。そのため、本番との挙動の差異が発生しないように、ローカル開発環境やテスト環境にも本番環境のデータベースと同様に定義されている状態が望ましいです。
migrationファイルを作成する
通常の開発環境のセットアップにあたってはdb:setup taskなどでdb/schema.rbからデータベースを構築します。しかしながら、db:migrateなどでmigrationファイルから構築した場合にも同様のデータベースを構築できることが望ましいです。そのため、一番最初のmigrationファイルとして、現在の移植元のシステムのデータベースと同様の環境を作成するmigrationファイルを作成することにしました。
比較的あたらしいシステムとはいえ、テーブル数は数十はあるので、さすがにこれをすべて手書きするのは大変です。なので可能な限り自動生成を試みます。
まずは移植元システムのローカル開発環境のdatabaseに接続した状態で、db:schema:dumpでdb/maja_schema.rbに既存のデータベースの内容をdumpしました。schema.rbとmigrationファイルは同じsyntaxで記述されているので、schema.rbの定義部分をmigrationファイルの#changeメソッドにそのまま流用が可能です。
これでテーブル定義部分は作成できました。
残りはschema.rbには出力されないview・function・triggerです。
幸い、migrationファイルには#executeメソッドで生SQLを実行する機能があります。これを#reversibleメソッドと組み合わせて以下のような形でmigrationファイルを作成しました。
db/maja_migrate/20250402090247_load_initial_schema.rb
※ ここでは一例としてfunctionの定義に関する部分だけをピックアップしました。
# frozen_string_literal: true class LoadInitialSchema < ActiveRecord::Migration[8.0] def change # (テーブルの定義) # (viewの定義) create_function :set_timestamp, <<~SQL CREATE FUNCTION set_timestamp () RETURNS TRIGGER LANGUAGE plpgsql AS $$ BEGIN IF NEW.updated_at = OLD.updated_at THEN NEW.updated_at := CURRENT_TIMESTAMP; END IF; RETURN NEW; END; $$ SQL # (そのほかのfunctionの定義) # triggerの定義 end private # 今後新規にfunctionを追加することはしたくないので、 # この処理は共通helperではなくこのmigration fileだけのhelperとして定義 def create_function(name, creation_sql) reversible do |dir| dir.up { execute creation_sql } dir.down { execute "DROP FUNCTION #{name}" } end end
schema.rbを作成する
続いてschema.rbを作成していくのですが、こちらはmigrationファイルとは異なり一筋縄ではいきません。1つ前のセクションでも軽く触れましたが、実はschema.rbにはview・triggerなどの定義が出力されません。これですとdb:setupでデータベースを作成した際にview・triggerが定義されていない状態になってしまうので、どうにかしてこれらが定義されるようにする必要があります。
Ruby on Rails 公式から提供されている対応策として、スキーマdumpをSQL形式に変更する、というやり方があります。
今回の要件は上記のドキュメントに記載されているユースケースそのものだったので、このオプションで対応しようと考えたのですが、これには1点問題がありました。それは「この設定はアプリケーション全体に対しての設定で、データベースごとに設定を変えられない」という点です。
移植先システムに元々あるデータベースのスキーマダンプはデフォルトのRuby形式になっています。SQL形式はRuby形式と比較して以下のようなデメリットがあるので、移植のために既存のスキーマダンプまでSQL形式には変更したくありません。
- そもそもRuby形式がデフォルトであり、こちらの方が一般的。
- SQL形式は
pg_dumpなど外部のツールへの依存が発生し、外部ツールのバージョンなどに起因したトラブルや差分が発生しうる。
この問題にはかなり頭を悩ませたのですが、最終的にはスキーマダンプ処理にパッチを当てて対処することにしました。
config/initializers/maja_schema_dump_behavior.rb
# frozen_string_literal: true # majaのDBはPostgreSQLのfunctionやtrigger, viewを活用しているが、 # これらは標準の`schema.rb`には出力されない # そのためmajaのDBだけ`structure.sql`形式で出力したいが、 # 標準では特定のconfigでだけformatを変える方法が無いので、該当の処理を上書いてそれを実現している module MajaSchemaDumpBehavior extend ::ActiveSupport::Concern def load_schema(db_config, format = ::ActiveRecord.schema_format, file = nil) case db_config.name in "maja" super(db_config, :sql, file) else super end end def dump_schema(db_config, format = ::ActiveRecord.schema_format) case db_config.name in "maja" super(db_config, :sql) else super end end end ActiveRecord::Tasks::DatabaseTasks.prepend MajaSchemaDumpBehavior
frameworkのコードにパッチを当てるというのもあまり好ましいことではないのですが、今回のパッチに関しては以下のようなあたりを鑑みて許容することにしました。
- 影響範囲がスキーマダンプ・ロード処理に閉じている。
- パッチ自体は小規模で、今後の本体の変更に追従するのも難しくないと思われる。
これで bin/rails db:maja:schema:dumpコマンドで移植元システムのデータベースが db/maja_structure.sqlにダンプされるようになりました。
微調整
最後に、bin/rails db:maja:migrateで生成されるdb/maja_structure.sqlを本番のデータベースの定義と付き合わせ、差分を完全に解消します。
まずは、activerecord gem内のpg_dumpコマンドを実行しているコードにputsを仕込み、Ruby on Railsがdumpするのと同じオプションで本番のデータベースのschemaをdumpします7。
この本番からdumpしたschemaとdb/maja_structure.sqlを比較したところ、細かい部分でまだ差分が残っていました。この差分は大した量ではなかったので、migrate後のdb/maja_structure.sqlが本番からのdumpと一致するまで、migrationファイルを手作業で調整しました。
まとめ
以上が、今回の移植におけるデータベース対応の全体像です8。改めて振り返ってみると思ったよりも色々なところでハマったり手間取ったりしてたな、とすでに懐かしいような気持ちになりました。
移植の本筋とは関係ないのですが、個人的には今回の作業を通してGoogle Cloudの知見が増えたのが一番嬉しい収穫でした。
かなり長い記事となってしまいましたが、最後までお読みいただきありがとうございました。続編としてGraphQL編もの投稿も予定しているので、ご興味がありましたらぜひ併せてお読みいただけると嬉しいです。
- インターネットからのアクセスが可能になるとはいえ、アクセスには通常のdatabaseレベルの認証に加えてGoogle Cloudの提供する認証も必須で要求されます。そのため、private IPに比べて著しく安全性が脅かされるわけではありません。↩
- VPC ネットワーク ピアリング 自体はprojectを跨いで設定できるのですが、Private Service Access ではそのような構成はサポートされていないようです。↩
- 「Endpoint」というリソースがあるのではなく、複数のリソースの組み合わせを「Endpoint」と呼んでいる、というのが初見では本当に難解でした...。↩
- 正確にはforwarding ruleの設定自体は可能なものの、有効に動作しないという挙動になります。↩
- この接続確認は、移植先のproject内のVMからpsqlコマンドで実施しました。↩
- 多分に主観が入っているとは思いますが、大抵の人にとってはSQLのPROCEDUREよりは汎用プログラミング言語で書かれた処理の方が理解しやすいのではないでしょうか...!↩
- このときのpg_dumpのオプションも紹介できればよかったのですが、どこにもメモしていませんでした。↩
- 他にもローカル開発用のDocker環境の整備や、SQL形式のdumpファイルを扱うためのpg_dump系コマンドの導入など細かい調整も行なっていますが、雑多になってしまうのでこの辺りは割愛します。↩