
こんにちは、データ本部のssxotaです。STORESでデータ基盤の保守開発を担当しています。
今回は、BigQueryから集計したデータをSlackで通知する仕組みをテンプレート化し、通知内容の追加や更新を容易にできるようにしたので紹介します。
これまで、BigQueryからのSlack通知は、Argo Workflowsを利用して実行されていました。ワークフロー内でBigQueryにクエリを発行し、結果を文字列に加工してSlack APIを呼び出すことで、社内の経営指標を日次で通知する仕組みが動いていました。

今回、こちらの記事でも紹介しているスタンダードプランの開始に伴い発足した重要プロジェクトのSlackチャンネルに対して、新たな指標で通知を追加して欲しいとの要望があり、通知方法を検討しました。
Slack通知の追加にあたっては、BIツールにもSlack通知機能があるため、そちらで代用できないかも考えました。
現在、STORESでは主にMetabaseをBIツールとして利用しており、Subscription機能によるSlack通知が可能です。Subscription機能を用いると、ダッシュボード内の各指標の通知ができ、一定代用は可能です。しかしながら、既存のSlack通知機能では直接Slack APIを呼び出し、Slack上のテキスト内に集計した値を埋め込んだり、ハイパーリンクとして売上ランキング上位のユーザーのサイトURLを付与したりする柔軟なテキスト表現が可能だったのですが、MetabaseのSubscription機能では、ダッシュボード内の各グラフがそのままSlack上に通知されるため、既存の通知機能のようなテキスト表現が難しい部分がありました。
また、使用できるSlackアプリがMetabase用のMetabotに限定されるため、こちらで用意したアプリが使えないという点もありました。(日々の通知が社内で定着するうえで、意外と重要な要素であると思います。)
上記の理由により、BIからの通知は利用せず、Argo Workflows上でSlack APIを呼び出す形式は変更しない方針としました。しかし、既存の仕組みでは、通知内容がハードコーディングされており、変更や追加の度にスクリプトの編集が必要でした。
そこで、この機会に通知内容をテンプレート化し、更新や追加が簡単にできる構成を目指しました。また、元々の通知処理はRustで書かれていましたが、データ基盤の主流言語がPythonであるため、このタイミングでPythonへの移行も行いました。
Slack通知の実装
Slack通知の実装内容を紹介します。今回は、以下のように売上/粗利と前日比、ユーザーごとのランキング、実績値と目標値の比較グラフを通知する方法を示します。
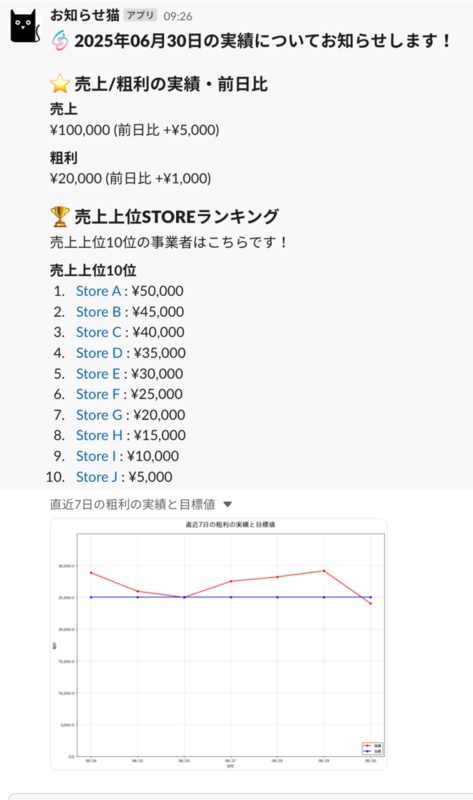
ちなみに、この少しレトロな猫のSlackアプリは、私が入社前から通知に使われていたアプリで、今回このタイミングでの切り替えも考えましたが、なんだかんだ愛着もありこのまま使わせて貰っています。
ディレクトリ/ファイル構成
今回の通知の仕組みの主なディレクトリ/ファイル構成は以下の通りです。
workflows/slack-notifier/ ├── templates/ # 通知テンプレート │ └── sample/ │ ├── notification.yaml # 通知テンプレート(YAML形式) │ └── queries/ # クエリの格納用ディレクトリ │ ├── top_sellers.sql │ ├── sales_and_profit.sql │ └── weekly_profit.sql ├── src/ # 通知機能のソースコード │ ├── main.py │ ├── notifier.py │ └── chart_generator.py ├── workflows/ # ArgoWorkflows上のworkflow定義 │ ├── workflow.yaml │ └── kustomization.yaml ├── compose.yaml ├── Dockerfile └── entrypoint.sh └── poetry.lock └── pyproject.toml └── .envrc
通知の追加は、templates以下に新しい通知用のテンプレートおよびデータ取得用のクエリを追加することで実現でき、ソースコードの編集が不要となる構成としています。
テンプレートファイルの構成
通知のテンプレートはYAMLファイルで定義しています。
name: "sample" description: "Sample notification template for blog" slack_channels: development: YYYYYY production: XXXXXX variables: today: "{{ now().strftime('%Y年%m月%d日') }}" sources: - name: "sales_and_profit" query: "sales_and_profit.sql" - name: "top_sellers" query: "top_sellers.sql" - name: "weekly_profit" query: "weekly_profit.sql" rankings: top_sellers: format: "<{top_sellers.url}|{top_sellers.store_name}> : {top_sellers.sales:currency}" limit: 10 images: - name: "weekly_profit_chart" source: "weekly_profit" type: "chart" title: "直近7日の粗利の実績と目標値" chart_type: "line" width: 1024 height: 768 x_axis: title: "日付" data_key: "date" format: "%m/%d" y_axis: title: "粗利" format: "{:,}" series: - name: "実績" data_key: "gross_profit" color: "red" - name: "目標" data_key: "target_profit" color: "blue" messages: - type: "blocks" blocks: - type: "header" text: ":storeslogo: {{ variables.today }}の実績についてお知らせします!" - type: "header" text: ":star: 売上/粗利の実績・前日比" - type: "markdown" text: | **売上** {sales_and_profit.sales:currency} (前日比 {sales_and_profit.sales_diff:currency_with_sign}) **粗利** {sales_and_profit.gross_profit:currency} (前日比 {sales_and_profit.gross_profit_diff:currency_with_sign}) - type: "header" text: ":trophy: 売上上位STOREランキング" - type: "markdown" text: | 売上上位10位の事業者はこちらです! **売上上位10位** {top_sellers:ranking} - type: "files" title: "直近7日の粗利の実績と目標値" image_ref: "weekly_profit_chart"
各セクションは以下のように定義しています。
name/description
テンプレートの名前/説明を指定します。
slack_channels
開発/本番環境ごとに通知を送信するSlackチャンネルのIDを指定します。 - .envrcに設定したGoogleプロジェクトごとに通知先チャンネルが開発/本番で切り替わります - なお、通知に使用するSlackアプリのトークンについても.envrc内で環境変数として定義しています
variables
日付などのテンプレート内で共通で使用する変数を定義できます。 以下は現在設定できる変数の例です。
variables: yesterday: "{{ (now() - timedelta(days=1)).strftime('%Y年%m月%d日') }}" this_month: "{{ now().strftime('%Y年%m月') }}" custom_var: "カスタム値"
sources
BigQueryから取得するデータをデータソースとして定義します。
データソースを参照する場合は{name.query内のcolumn名}という形式で指定します。
- name : データソース名を指定
- query : queries配下のsqlファイルを指定
今回の実装では、以下のサンプルクエリをデータソースとして使用しています。
sales_and_profit.sql
WITH sales_data AS ( SELECT CURRENT_DATE() AS date, 100000 AS sales, 20000 AS gross_profit, 5000 AS sales_diff, 1000 AS gross_profit_diff ) SELECT * FROM sales_data;
top_sellers.sql
WITH top_sellers AS ( SELECT ROW_NUMBER() OVER (ORDER BY sales DESC) AS rank, CONCAT('https://example.com/store/', store_id) AS url, store_name, sales FROM ( SELECT 1 AS store_id, 'Store A' AS store_name, 50000 AS sales UNION ALL SELECT 2 AS store_id, 'Store B' AS store_name, 45000 AS sales ... UNION ALL SELECT 10 AS store_id, 'Store J' AS store_name, 5000 AS sales ) ) SELECT * FROM top_sellers WHERE rank <= 10;
weekly_profit.sql
WITH weekly_profit AS ( SELECT DATE_SUB(CURRENT_DATE(), INTERVAL seq DAY) AS date, 20000 + CAST(RAND() * 10000 AS INT64) AS gross_profit, 25000 AS target_profit FROM UNNEST(GENERATE_ARRAY(0, 6)) AS seq ) SELECT * FROM weekly_profit;
値のフォーマット
データソースの値を表示する際に以下のフォーマットを指定可能です。
:number- 3桁区切りの数値- 例:
{daily_data.count:number}→1,234
- 例:
:number_with_sign- 3桁区切りの数値(正の値に「+」記号、0に「±」記号)- 例:
{daily_data.count_diff:number_with_sign}→+1,234/-567/±0
- 例:
:currency- 通貨表示(円)- 例:
{daily_data.sales:currency}→¥1,234
- 例:
:currency_with_sign- 通貨表示(円、正の値に「+」記号、0に「±」記号)- 例:
{daily_data.sales_diff:currency_with_sign}→+¥1,234/-¥567/±¥0
- 例:
:percentage- パーセント表示- 例:
{daily_data.ratio:percentage}→12.3%
- 例:
:ranking- ランキング表示- 使用例:
{ranking_name:ranking} - 事前に
rankings内での定義が必要
- 使用例:
rankings
sourcesで定義したデータソースを参照して、ランキング形式で表示するフォーマットを定義します。
今回は以下のようにSlackのハイパーリンク形式に沿う形でフォーマットを定義しています。
yaml
format: "<{top_sellers.url}|{top_sellers.store_name}> : {top_sellers.sales:currency}"
images
グラフ画像を定義します。
現在は折れ線グラフのみの対応ですが、sourcesで定義したデータソースから画像を生成可能です。
内部的にはグラフ生成にmatplotlibを利用しているため、画像サイズ、タイトル、線種などのmatplotlibで設定可能なオプションは一定設定できるよう対応しています。
messages
Slackに送信するメッセージを定義します。
以下のblocksとfilesが定義できます。
blocks
Slack APIで定義されているblock-kitに対応する形で、通知メッセージを記述できます。 現在は、blocks内のheader、markdownが設定でき、markdown形式での記述が可能です。
files
imagesで定義したグラフ画像を添付可能です。
Pythonスクリプト
srcディレクトリ内のPythonスクリプトについて、処理内容を紹介します。
main.py
Slack通知のエントリーポイントです。環境変数の検証、コマンドライン引数の解析、テンプレートの読み込みと検証を行い、Notifierクラスを使用して通知を生成・送信しています。
main.py
""" Slack Notifier main script """ import argparse import os from pathlib import Path from dotenv import load_dotenv from .notifier import Notifier def validate_environment(): """Validate required environment variables""" required_vars = ["GCP_PROJECT_ID", "SLACK_APP_TOKEN"] missing_vars = [var for var in required_vars if not os.getenv(var)] if missing_vars: raise ValueError(f"Missing required environment variables: {', '.join(missing_vars)}") def parse_args(): parser = argparse.ArgumentParser(description='Slack Notification Generator') parser.add_argument( 'template', type=str, help='Template name. Will look for templates/{template_name}/notification.yml' ) return parser.parse_args() def get_template_path(template_name: str) -> Path: """Get template path with proper structure""" template_dir = Path(__file__).parent.parent / 'templates' / template_name template_path = template_dir / 'notification.yml' return template_path def main(): # Parse command line arguments args = parse_args() # Load environment variables load_dotenv() try: # Validate environment variables validate_environment() template_path = get_template_path(args.template) if not template_path.exists(): raise FileNotFoundError( f"Template file not found: {template_path}\n" f"Expected structure: templates/{args.template}/notification.yml" ) # Initialize and run notifier notifier = Notifier(str(template_path)) notifier.generate_and_send_notification() except Exception as e: print(f"Error occurred: {e}") raise if __name__ == '__main__': main()
notifier.py
通知を生成し送信するためのNotifierクラスを定義しており、テンプレートの読み込み、メッセージ作成、送信のメインロジックが書かれています。
- テンプレートの読み込み/検証
- テンプレート上で定義されたデータソースに対して、BigQueryにクエリを発行し
pandasのDataFrame化 - 読み込んだ
DataFrameから画像生成処理用のクラスChartGeneratorを用いて画像生成 - テンプレートと
DataFrameのマッピング、フォーマットの解析を行い、メッセージを作成 - python-slack-sdkによるSlackへのメッセージ/ファイル送信
notifier.py
""" Notification Template """ import os import re from datetime import datetime, timedelta from pathlib import Path from typing import Dict, Any, List import pandas as pd import yaml from google.cloud import bigquery from jinja2 import Environment, FileSystemLoader from slack_sdk import WebClient from slack_sdk.errors import SlackApiError from .chart_generator import ChartGenerator class Notifier: def __init__(self, template_path: str): self.template_dir = Path(template_path).parent self.template = self._load_template(template_path) self.jinja_env = Environment( loader=FileSystemLoader(str(self.template_dir)), extensions=['jinja2.ext.do'] ) self.chart_generator = ChartGenerator() self.bq_client = bigquery.Client(project=os.getenv("GCP_PROJECT_ID")) self.slack_client = WebClient(token=os.environ["SLACK_APP_TOKEN"]) def _load_template(self, path: str) -> Dict[str, Any]: """Load and validate template""" with open(path, 'r') as f: template = yaml.safe_load(f) self._validate_template(template) return template def _validate_template(self, template: Dict[str, Any]) -> None: """Validate template structure""" required_keys = ['name', 'messages'] for key in required_keys: if key not in template: raise ValueError(f"Template missing required key: {key}") if 'slack_channels' not in template: raise ValueError("Template missing slack_channels in notification section") if not isinstance(template['slack_channels'], dict): raise ValueError("slack_channels must be a dictionary") if 'development' not in template['slack_channels']: raise ValueError("slack_channels must contain 'development' key") if 'production' not in template['slack_channels']: raise ValueError("slack_channels must contain 'production' key") if not isinstance(template['messages'], list): raise ValueError("Messages must be a list") # Validate rankings configuration rankings = template.get('rankings', {}) for ranking_name, config in rankings.items(): if 'format' not in config: raise ValueError(f"Ranking {ranking_name} missing format") if 'limit' not in config: raise ValueError(f"Ranking {ranking_name} missing limit") if not isinstance(config['limit'], int) or config['limit'] <= 0: raise ValueError(f"Ranking {ranking_name} has invalid limit: {config['limit']}") # Collect all source names for validation source_names = {source['name'] for source in template.get('sources', [])} # Validate that all ranking sources exist for ranking_name in rankings: if ranking_name not in source_names: raise ValueError(f"Ranking {ranking_name} references undefined source") for message in template['messages']: if 'type' not in message: raise ValueError("Message missing type field") message_type = message['type'] if message_type == 'text': if 'text' not in message: raise ValueError("Text message missing text field") elif message_type == 'blocks': if 'blocks' not in message: raise ValueError("Blocks message missing blocks field") if not isinstance(message['blocks'], list): raise ValueError("Blocks must be a list") elif message_type == 'files': if 'image_ref' not in message: raise ValueError("Files message missing image_ref field") if 'title' not in message: raise ValueError("Files message missing title field") else: raise ValueError(f"Unknown message type: {message_type}") def _render_variables(self) -> Dict[str, Any]: """Render template variables with Jinja2""" context = { 'now': datetime.now, 'timedelta': timedelta, 'strftime': datetime.strftime, } variables = {} for key, value in self.template.get('variables', {}).items(): if isinstance(value, str): try: template = self.jinja_env.from_string(value) variables[key] = template.render(**context) except Exception as e: print(f"Error rendering variable {key}: {e}") raise else: variables[key] = value return variables def _load_data(self, sources: List[Dict[str, str]]) -> Dict[str, pd.DataFrame]: """Load data from SQL queries""" data = {} for source in sources: query_path = self.template_dir / 'queries' / source['query'] try: with open(query_path, 'r') as f: query = f.read() print(f"Executing query from {source['query']}") query_job = self.bq_client.query(query) results = query_job.result() data[source['name']] = results.to_dataframe() print(f"Query {source['query']} returned {len(data[source['name']])} rows") except Exception as e: print(f"Error executing query {source['query']}: {e}") raise return data def _format_value(self, value: Any, format_type: str) -> str: """Format values according to template specifications""" try: if pd.isna(value): return "N/A" if format_type == 'number': return f'{int(value):,}' elif format_type == 'number_with_sign': if value > 0: return f'+{int(value):,}' elif value == 0: return f'±0' else: return f'{int(value):,}' elif format_type == 'currency': return f'¥{int(value):,}' elif format_type == 'currency_with_sign': if value > 0: return f'+¥{int(value):,}' elif value == 0: return f'±¥0' else: return f'-¥{abs(int(value)):,}' elif format_type == 'percentage': return f'{float(value):.1f}%' return str(value) except Exception as e: print(f"Error formatting value {value} with type {format_type}: {e}") return str(value) def _process_template_string(self, template_str: str, data: Dict[str, pd.DataFrame]) -> str: """Process a template string containing variable references""" def replace_var(match): var_ref = match.group(1) format_type = None if ':' in var_ref: var_ref, format_type = var_ref.split(':') try: if format_type == 'ranking': ranking_config = self.template.get('rankings', {}).get(var_ref) if not ranking_config: raise ValueError(f"Ranking configuration not found for {var_ref}") df = data[var_ref] if not isinstance(df, pd.DataFrame): raise ValueError(f"Data source '{var_ref}' is not a DataFrame") items = [] for idx, row in df.head(ranking_config['limit']).iterrows(): # Create a context with all available data sources context = data.copy() # Add current row data to the specific ranking source context[var_ref] = row.to_dict() formatted = self._process_template_string(ranking_config['format'], context) items.append(f"{idx+1}. {formatted}") return "\n".join(items) if '.' not in var_ref: raise ValueError(f"Invalid variable reference format: {var_ref}. Must use source.field format.") source_name, field = var_ref.split('.') if source_name not in data: raise KeyError(f"Data source '{source_name}' not found") source_data = data[source_name] # Handle both DataFrame and dict cases if isinstance(source_data, pd.DataFrame): if source_data.empty: return "N/A" if field not in source_data.columns: raise KeyError(f"Field '{field}' not found in data source '{source_name}'") value = source_data.iloc[0][field] elif isinstance(source_data, dict): if field not in source_data: raise KeyError(f"Field '{field}' not found in data source '{source_name}'") value = source_data[field] else: raise ValueError(f"Data source '{source_name}' is neither a DataFrame nor a dict") if format_type: return self._format_value(value, format_type) return str(value) except Exception as e: print(f"Error processing variable reference {var_ref}: {e}") return "N/A" return re.sub(r'\{([^}]+)\}', replace_var, template_str) def _collect_sources(self) -> List[Dict[str, str]]: """Collect all data sources and check for duplicates""" sources = self.template.get('sources', []) seen = {} unique_sources = [] for source in sources: key = (source['name'], source['query']) if key in seen: raise ValueError(f"Duplicate source found: name='{source['name']}', query='{source['query']}'. First defined at index {seen[key]}, duplicated at index {len(unique_sources)}") seen[key] = len(unique_sources) unique_sources.append(source) return unique_sources def _process_block(self, block: Dict[str, Any], data: Dict[str, pd.DataFrame], variables: Dict[str, Any]) -> Dict[str, Any]: """Process a single block based on its type""" block_type = block['type'] processed_block = {"type": block_type} if block_type == "header": text = self.jinja_env.from_string(block['text']).render(variables=variables) text = self._process_template_string(text, data) processed_block["text"] = { "type": "plain_text", "text": text } elif block_type == "markdown": text = self.jinja_env.from_string(block['text']).render(variables=variables) text = self._process_template_string(text, data) processed_block["text"] = text return processed_block def _get_slack_channel(self) -> str: """Get Slack channel based on GCP project ID""" project_id = os.getenv("GCP_PROJECT_ID") channels = self.template['slack_channels'] if project_id == "xxxxxxxx": # set your prodcution project return channels['production'] else: return channels['development'] def _send_to_slack(self, blocks: List[Dict[str, Any]], text: str) -> None: """Send blocks to Slack""" try: channel = self._get_slack_channel() # Provide default text when blocks are present fallback_text = text or "Notification from Data Pipeline" self.slack_client.chat_postMessage( channel=channel, blocks=blocks, text=fallback_text ) print(f"Successfully sent notification to Slack channel: {channel}") except SlackApiError as e: print(f"Error in Slack communication: {e.response['error']}") raise def _generate_chart(self, image_config: Dict[str, Any], data: Dict[str, pd.DataFrame]) -> str: """Generate chart and return its file path""" try: # Get image name first image_name = image_config['name'] # Get chart data from the specified source if 'source' not in image_config: raise ValueError("Chart configuration must include 'source'") source_name = image_config['source'] if source_name not in data: raise KeyError(f"Chart data source '{source_name}' not found") source_data = data[source_name] if not isinstance(source_data, pd.DataFrame): raise ValueError(f"Chart data source '{source_name}' is not a DataFrame") if source_data.empty: raise ValueError(f"Chart data source '{source_name}' is empty") # Generate chart using the chart generator return self.chart_generator.generate_chart(source_data, image_config) except Exception as e: print(f"Error generating chart for {image_name}: {e}") return None def _process_message(self, message: Dict[str, Any], data: Dict[str, pd.DataFrame], variables: Dict[str, Any], images: Dict[str, str]) -> None: """Process a single message based on its type""" try: message_type = message['type'] if message_type == 'text': self._send_to_slack([], message['text']) print(f"Sent text message") elif message_type == 'blocks': processed_blocks = [] for block in message['blocks']: processed_block = self._process_block(block, data, variables) if processed_block: processed_blocks.append(processed_block) if processed_blocks: self._send_to_slack(processed_blocks, '') print(f"Sent {len(processed_blocks)} blocks") elif message_type == 'files': image_name = message['image_ref'] if image_name in images: try: channel = self._get_slack_channel() with open(images[image_name], 'rb') as f: self.slack_client.files_upload_v2( channel=channel, title=message['title'], initial_comment=message.get('initial_comment', ''), file_uploads=[{ "file": f, "title": message['title'] }] ) print(f"Uploaded file {image_name}") except Exception as e: print(f"Error uploading file {image_name}: {e}") finally: try: if os.path.exists(images[image_name]): os.remove(images[image_name]) print(f"Removed temporary file: {images[image_name]}") except Exception as e: print(f"Failed to remove temporary file {images[image_name]}: {e}") else: print(f"Image {image_name} not found") else: print(f"Unknown message type: {message_type}") except Exception as e: print(f"Error processing message of type {message.get('type', 'unknown')}: {e}") def generate_and_send_notification(self) -> None: """Generate and send notification""" try: # Render variables variables = self._render_variables() # Collect and load all data sources = self._collect_sources() data = self._load_data(sources) # Generate images images = {} for image_config in self.template.get('images', []): if image_config['type'] == 'chart': image_path = self._generate_chart(image_config, data) if image_path: images[image_config['name']] = image_path # Process messages in order for message in self.template['messages']: self._process_message(message, data, variables, images) except Exception as e: print(f"Error generating notification: {e}") raise
chart_generator.py
データと設定に基づいてグラフを作成するChartGeneratorクラスを定義しています。
Matplotlibを使用して折れ線グラフを作成し、タイトル、軸ラベル、凡例などを設定し、画像として保存します。
chart_generator.py
""" Chart Generator """ import os import tempfile from pathlib import Path from typing import Dict, Any import japanize_matplotlib import matplotlib.dates as mdates import matplotlib.pyplot as plt import numpy as np import pandas as pd class ChartGenerator: def __init__(self, image_dir: str = None): self.image_dir = Path(image_dir) if image_dir else Path(__file__).parent.parent / 'images' self.image_dir.mkdir(exist_ok=True) def generate_chart(self, data: pd.DataFrame, config: Dict[str, Any]) -> str: """Generate chart based on configuration""" chart_type = config.get('chart_type', 'line') if chart_type == 'line': return self._generate_line_chart(data, config) def _generate_line_chart(self, data: pd.DataFrame, config: Dict[str, Any]) -> str: """Generate line chart""" # Create figure and axis fig = plt.figure(figsize=(config.get('width', 1024) / 80, config.get('height', 768) / 80)) ax = plt.gca() # Set title if configured if 'title' in config: plt.title(config['title'], pad=20, fontsize=18) # Plot each series for series in config['y_axis']['series']: plt.plot( data[config['x_axis']['data_key']], data[series['data_key']], color=series.get('color', 'blue'), label=series.get('name', ''), linewidth=series.get('line_width', 2), marker=series.get('marker', 'o'), markersize=series.get('marker_size', 5) ) # Add value labels if configured if series.get('show_values', False): for x, y in zip(data[config['x_axis']['data_key']], data[series['data_key']]): plt.annotate( f'{int(y):,}', (x, y), xytext=(0, 10), textcoords='offset points', ha='center', va='bottom', fontsize=10 ) # Configure X-axis if 'format' in config['x_axis']: ax.xaxis.set_major_formatter(mdates.DateFormatter(config['x_axis']['format'])) if config['x_axis'].get('rotate_labels', False): plt.gcf().autofmt_xdate() plt.xlabel(config['x_axis'].get('title', '')) if 'margin' in config['x_axis']: plt.margins(x=config['x_axis']['margin']) # Configure Y-axis plt.ylabel(config['y_axis'].get('title', '')) if 'format' in config['y_axis']: ax.yaxis.set_major_formatter(lambda x, p: config['y_axis']['format'].format(x)) if 'min' in config['y_axis']: ymin = config['y_axis']['min'] else: ymin = 0 if 'max' in config['y_axis']: ymax = config['y_axis']['max'] else: max_value = max(max(data[s['data_key']]) for s in config['y_axis']['series']) ymax = max_value * config['y_axis'].get('max_scale', 1.2) plt.ylim(ymin, ymax) if 'tick_count' in config['y_axis']: ax.yaxis.set_major_locator(plt.MaxNLocator(config['y_axis']['tick_count'])) # Add grid plt.grid(True, linestyle='--', alpha=0.7) # Add legend if any(s.get('name') for s in config['y_axis']['series']): legend_config = config.get('legend', {}) plt.legend( loc=legend_config.get('position', 'lower right'), framealpha=legend_config.get('alpha', 0.8), edgecolor=legend_config.get('edge_color', 'black') ) # Adjust layout plt.tight_layout() # Save the figure output_path = str(self.image_dir / f"{config.get('name', 'chart')}.png") plt.savefig(output_path, dpi=80, bbox_inches='tight') plt.close() return output_path
Workflowの定義
Pythonスクリプトの実行においては、entrypoint.shの引数としてテンプレート名を受け取り、mainスクリプトを実行する処理を記述したうえで、以下のようにworkflows/workflow.yaml上にWorkflowTemplateを定義して実行しています。
- name: sample-notify-workflow
container:
image: image-name
command:
- ./entrypoint.sh
- sample
まとめ
今回、Slack通知のテンプレート化を行い、BigQueryの集計結果に基づく通知内容の追加や変更が容易になる構成を実現しました。
実装してみた感想としては、YAMLテンプレートでのグラフ記述は、グラフ種類ごとの実装対応やオプションの指定が煩雑でBIツールに利点があると感じる一方で、今回の仕組みのようにテキスト表現を柔軟に制御できることで、通知内容をコンパクトにし、視認性を向上させることができる点にはメリットがあると感じています。
今後もプロジェクトの状況変化によって通知内容の変更や追加が求められることが予想されるため、今回の仕組みを用いて事業の要求に迅速に対応していきたいと考えています。